 Azərbaycanca
Azərbaycanca Deutsch
Deutsch 日本語
日本語 Lietuvos
Lietuvos සිංහල
සිංහල Türkçe
Türkçe Українська
Українська United State
United State
Bu madde, ; zira herhangi bir maddeden bu maddeye verilmiş bir bağlantı yoktur. (Nisan 2025) |
Bulanık geri çağırma teknikleri ve Bulanık küme teorisine dayanmaktadır. İki klasik bulanık geri çağırma modeli vardır: Karma Min ve Maks (MMM) ve Paice modeli. Her iki model de sorgu ağırlıklarını değerlendirmenin bir yolunu sağlamaz, ancak bu algoritması tarafından dikkate alınır.
Karma Min ve Maks modeli (MMM)
| ]Bulanık küme teorisinde, bir eleman, verilen A kümesine, geleneksel üyelik seçimi (elemandır/eleman değildir) yerine, değişen derecelerde üyeliğe (örneğin d A) sahiptir.
MMM'de her endeks teriminin kendisiyle ilişkili bir bulanık kümesi vardır. Bir belgenin A endeks terimine göre ağırlığı, belgenin A ile ilişkili bulanık kümedeki üyelik derecesi olarak kabul edilir. Birleşim ve kesişim için üyelik derecesi, Bulanık küme teorisinde aşağıdaki gibi tanımlanır:
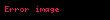
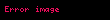
Buna göre, A veya B biçimindeki bir sorgu için alınması gereken belgeler, A ve B kümelerinin birleşimiyle ilişkili bulanık kümede olmalıdır. Benzer şekilde, A ve B biçimindeki bir sorgu için alınması gereken belgeler, iki kümenin kesişimiyle ilişkili bulanık kümede olmalıdır. Dolayısıyla, bir belgenin veya sorgusuna benzerliğini max(d A, d B ) ve belgenin ve sorgusuna benzerliğini min(d A, d B ) olarak tanımlamak mümkündür. MMM modeli, sorgu-belge benzerliğini, minimum ve maksimum belge ağırlıklarının doğrusal bir kombinasyonu olarak ele alarak Boole operatörlerini yumuşatmaya çalışır.
dA1, dA2, ..., d An endeks terim ağırlıklarına sahip bir D belgesi verildiğinde A1, A2, ..., An, ve sorguları:
Q veya = (A 1 veya A 2 ... veya A n )
S ve = (A 1 ve A 2 ... ve A n )
MMM modelinde sorgu-belge benzerliği aşağıdaki şekilde hesaplanır:
SlM(Qor, D) = Cor1 * max(dA1, dA2, ..., dAn) + Cor2 * min(dA1, dA2, ..., dAn)
SlM(Qand, D) = Cand1 * min(dA1, dA2, ..., dAn) + Cand2 * max(dA1, dA2 ..., dAn)
Burada C or1, C or2 veya operatörü için "yumuşaklık" katsayılarıdır ve C and1, C and2 ve operatörü için yumuşaklık katsayılarıdır. Bir veya sorgusunu ele alırken belge ağırlıklarının maksimum olanına daha fazla önem vermek istediğimizden ve bir ve sorgusunu ele alırken de minimum olanına daha fazla önem vermek istediğimizden, genellikle C or1 > C or2 ve C and1 > C and2 elde ederiz. Basitleştirmek için genellikle C or1 = 1 - C or2 ve C and1 = 1 - C and2 olduğu varsayılır.
Lee ve Fox deneyleri, en iyi performansın genellikle C ve 1'in [0,5, 0,8] aralığında ve C veya1 > 0,2 olduğunda ortaya çıktığını göstermektedir. Genel olarak, MMM'nin hesaplama maliyeti düşüktür ve alma etkinliği Standart Boole modeline göre çok daha iyidir.
Paice modeli
| ]modeli MMM modelinin genel bir uzantısıdır. Sadece endeks terimleri için minimum ve maksimum ağırlıkları dikkate alan MMM modeliyle karşılaştırıldığında, Paice modeli benzerliği hesaplamak için tüm terim ağırlıklarını dahil eder:

Burada r sabit bir katsayı ve wdi, ve sorguları için artan sırada ve veya sorguları için azalan sırada düzenlenmiştir. n = 2 olduğunda Paice modeli MMM modeliyle aynı davranışı göstermektedir.
Lee ve Fox'un deneyleri, r'yi ve sorguları için 1,0'a ve veya sorguları için 0,7'ye ayarlamanın iyi bir geri alma etkinliği sağladığını göstermiştir. Bu modelin hesaplama maliyeti MMM modeline göre daha yüksektir. Bunun nedeni, MMM modelinin her seferinde bir ve veya veya ifadesi dikkate alındığında yalnızca bir dizi terim ağırlığının en düşük veya en yüksek değerinin belirlenmesini gerektirmesidir; bu da O(n) içinde yapılabilir. Paice modeli, bir ve ifadesinin mi yoksa bir veya ifadesinin mi dikkate alındığına bağlı olarak terim ağırlıklarının artan veya azalan düzende sıralanmasını gerektirir. Bu en azından 0(n log n) sıralama algoritması gerektirir. Ayrıca, çok miktarda kayan nokta hesaplamasına da ihtiyaç vardır.
Standart Boole modeline göre iyileştirmeler
| ]Lee ve Fox Standart Boole modelini üç test koleksiyonu olan CISI, CACM ve INSPEC ile MMM ve Paice modelleriyle karşılaştırdı. Ortalama hassasiyet iyileştirmesi için bildirilen sonuçlar şunlardır:
| ÇİSİ | CACM | DENETLEME | |
|---|---|---|---|
| MMM | %68 | %109 | %195 |
| Paice | %77 | %104 | %206 |
Bunlar Standart modele göre çok iyi iyileştirmeler. MMM, Paice ve P-norm sonuçlarına oldukça yakın olup, bu da onun çok iyi bir teknik olabileceğini ve üçü arasında en verimli olanı olduğunu göstermektedir.
Yakın zamanda yapılan çalışmalar
| ]2005 yılında Kang et al kavram tanımlamasına göre dizinlenen bulanık bir alma sistemi tasarladılar.
Belgelere saf Tf-idf yaklaşımıyla baktığımızda, durdurma sözcüklerini çıkarsak bile, belgenin konusuyla diğerlerinden daha alakalı sözcükler olacak ve aynı terim sıklığına sahip oldukları için aynı ağırlığa sahip olacaklardır. Bir sorgudaki kullanıcı amacını hesaba katarsak, bir belgenin terimlerini daha iyi değerlendirebiliriz. Her terim, o kavramın o belge için önemini ifade eden belirli bir sözlük zincirindeki bir kavram olarak tanımlanabilir.
En çok alınan 5 belgenin ortalama Paice ve P-norm'a göre iyileştirildiğini bildiriyorlar.
Zadrozny bulanık bilgi alma modelini yeniden ele aldı. Ayrıca bulanık genişletilmiş Boole modelini şu şekilde genişletiyor:
- dilsel terimlerin anahtar kelimelerin önem ağırlıkları olarak varsayılması da belgelerde
- belgelerin ve sorguların temsiline ilişkin belirsizliği dikkate alarak
- Belgelerin ve sorguların temsilindeki dilsel terimlerin yorumlanması ve Zadeh'in bulanık mantığı (dilsel ifadelerin hesabı) açısından eşleştirilmesi
- Önerilen modelin bazı pragmatik yönlerini, özellikle de belgeleri ve sorguları dizinleme tekniklerini ele alma
Önerilen model, metinsel bilginin gösterimi ve geri çağrılmasıyla ilgili hem belirsizlik hem de belirsizliklerin kavranmasını mümkün kılmaktadır.
Ayrıca bakınız
| ]Daha fazla okuma
| ]S. Betrabet; M. Koushik; W. Lee (1992), Information Retrieval: Algorithms and Data structures; Extended Boolean model, Prentice-Hall, Inc., 28 Eylül 2013 tarihinde kaynağından arşivlendi9 Eylül 2017 Birden fazla yazar-name-list parameters kullanıldı (); |ad= ve |soyadı= eksik ()
Referanslar
| ]- ^ Fox, E. A.; S. Sharat (1986), A Comparison of Two Methods for Soft Boolean Interpretation in Information Retrieval, Technical Report TR-86-1, Virginia Tech, Department of Computer Science
- ^ a b c Lee, W. C.; E. A. Fox (1988), Experimental Comparison of Schemes for Interpreting Boolean Queries
- ^ Paice, C. D. (1984), Soft Evaluation of Boolean Search Queries in Information Retrieval Systems, Information Technology, Res. Dev. Applications, 3(1), 33-42
- ^ Kang, Bo-Yeong; Dae-Won Kim; Hae-Jung Kim (2005), "Fuzzy Information Retrieval Indexed by Concept Identification", Text, Speech and Dialogue, Lecture Notes in Computer Science, 3658, Springer Berlin / Heidelberg, ss. 179-186, doi:10.1007/11551874_23, ISBN
- ^ Zadrozny, Sławomir; Nowacka, Katarzyna (2009), "Fuzzy information retrieval model revisited", Fuzzy Sets and Systems, Elsevier North-Holland, Inc., 160 (15), ss. 2173-2191, doi:10.1016/j.fss.2009.02.012
wikipedia, wiki, viki, vikipedia, oku, kitap, kütüphane, kütübhane, ara, ara bul, bul, herşey, ne arasanız burada,hikayeler, makale, kitaplar, öğren, wiki, bilgi, tarih, yukle, izle, telefon için, turk, türk, türkçe, turkce, nasıl yapılır, ne demek, nasıl, yapmak, yapılır, indir, ücretsiz, ücretsiz indir, bedava, bedava indir, mp3, video, mp4, 3gp, jpg, jpeg, gif, png, resim, müzik, şarkı, film, film, oyun, oyunlar, mobil, cep telefonu, telefon, android, ios, apple, samsung, iphone, xiomi, xiaomi, redmi, honor, oppo, nokia, sonya, mi, pc, web, computer, bilgisayar
Vikipedi ozgur ansiklopedi Bu madde oksuz maddedir zira herhangi bir maddeden bu maddeye verilmis bir baglanti yoktur Lutfen ilgili maddelerden bu sayfaya baglanti vermeye calisin Nisan 2025 Bulanik geri cagirma teknikleri ve Bulanik kume teorisine dayanmaktadir Iki klasik bulanik geri cagirma modeli vardir Karma Min ve Maks MMM ve Paice modeli Her iki model de sorgu agirliklarini degerlendirmenin bir yolunu saglamaz ancak bu algoritmasi tarafindan dikkate alinir Karma Min ve Maks modeli MMM span Bulanik kume teorisinde bir eleman verilen A kumesine geleneksel uyelik secimi elemandir eleman degildir yerine degisen derecelerde uyelige ornegin d A sahiptir MMM de her endeks teriminin kendisiyle iliskili bir bulanik kumesi vardir Bir belgenin A endeks terimine gore agirligi belgenin A ile iliskili bulanik kumedeki uyelik derecesi olarak kabul edilir Birlesim ve kesisim icin uyelik derecesi Bulanik kume teorisinde asagidaki gibi tanimlanir dA B min dA dB displaystyle d A cap B min d A d B dA B max dA dB displaystyle d A cup B max d A d B Buna gore A veya B bicimindeki bir sorgu icin alinmasi gereken belgeler A ve B kumelerinin birlesimiyle iliskili bulanik kumede olmalidir Benzer sekilde A ve B bicimindeki bir sorgu icin alinmasi gereken belgeler iki kumenin kesisimiyle iliskili bulanik kumede olmalidir Dolayisiyla bir belgenin veya sorgusuna benzerligini max d A d B ve belgenin ve sorgusuna benzerligini min d A d B olarak tanimlamak mumkundur MMM modeli sorgu belge benzerligini minimum ve maksimum belge agirliklarinin dogrusal bir kombinasyonu olarak ele alarak Boole operatorlerini yumusatmaya calisir dA1 dA2 d An endeks terim agirliklarina sahip bir D belgesi verildiginde A1 A2 An ve sorgulari Q veya A 1 veya A 2 veya A n S ve A 1 ve A 2 ve A n MMM modelinde sorgu belge benzerligi asagidaki sekilde hesaplanir SlM Qor D Cor1 max dA1 dA2 dAn Cor2 min dA1 dA2 dAn SlM Qand D Cand1 min dA1 dA2 dAn Cand2 max dA1 dA2 dAn Burada C or1 C or2 veya operatoru icin yumusaklik katsayilaridir ve C and1 C and2 ve operatoru icin yumusaklik katsayilaridir Bir veya sorgusunu ele alirken belge agirliklarinin maksimum olanina daha fazla onem vermek istedigimizden ve bir ve sorgusunu ele alirken de minimum olanina daha fazla onem vermek istedigimizden genellikle C or1 gt C or2 ve C and1 gt C and2 elde ederiz Basitlestirmek icin genellikle C or1 1 C or2 ve C and1 1 C and2 oldugu varsayilir Lee ve Fox deneyleri en iyi performansin genellikle C ve 1 in 0 5 0 8 araliginda ve C veya1 gt 0 2 oldugunda ortaya ciktigini gostermektedir Genel olarak MMM nin hesaplama maliyeti dusuktur ve alma etkinligi Standart Boole modeline gore cok daha iyidir Paice modeli span modeli MMM modelinin genel bir uzantisidir Sadece endeks terimleri icin minimum ve maksimum agirliklari dikkate alan MMM modeliyle karsilastirildiginda Paice modeli benzerligi hesaplamak icin tum terim agirliklarini dahil eder S D Q i 1nri 1 wdi j 1nrj 1 displaystyle S D Q sum i 1 n frac r i 1 w di sum j 1 n r j 1 Burada r sabit bir katsayi ve wdi ve sorgulari icin artan sirada ve veya sorgulari icin azalan sirada duzenlenmistir n 2 oldugunda Paice modeli MMM modeliyle ayni davranisi gostermektedir Lee ve Fox un deneyleri r yi ve sorgulari icin 1 0 a ve veya sorgulari icin 0 7 ye ayarlamanin iyi bir geri alma etkinligi sagladigini gostermistir Bu modelin hesaplama maliyeti MMM modeline gore daha yuksektir Bunun nedeni MMM modelinin her seferinde bir ve veya veya ifadesi dikkate alindiginda yalnizca bir dizi terim agirliginin en dusuk veya en yuksek degerinin belirlenmesini gerektirmesidir bu da O n icinde yapilabilir Paice modeli bir ve ifadesinin mi yoksa bir veya ifadesinin mi dikkate alindigina bagli olarak terim agirliklarinin artan veya azalan duzende siralanmasini gerektirir Bu en azindan 0 n log n siralama algoritmasi gerektirir Ayrica cok miktarda kayan nokta hesaplamasina da ihtiyac vardir Standart Boole modeline gore iyilestirmeler span Lee ve Fox Standart Boole modelini uc test koleksiyonu olan CISI CACM ve INSPEC ile MMM ve Paice modelleriyle karsilastirdi Ortalama hassasiyet iyilestirmesi icin bildirilen sonuclar sunlardir CISI CACM DENETLEMEMMM 68 109 195Paice 77 104 206 Bunlar Standart modele gore cok iyi iyilestirmeler MMM Paice ve P norm sonuclarina oldukca yakin olup bu da onun cok iyi bir teknik olabilecegini ve ucu arasinda en verimli olani oldugunu gostermektedir Yakin zamanda yapilan calismalar span 2005 yilinda Kang et al kavram tanimlamasina gore dizinlenen bulanik bir alma sistemi tasarladilar Belgelere saf Tf idf yaklasimiyla baktigimizda durdurma sozcuklerini cikarsak bile belgenin konusuyla digerlerinden daha alakali sozcukler olacak ve ayni terim sikligina sahip olduklari icin ayni agirliga sahip olacaklardir Bir sorgudaki kullanici amacini hesaba katarsak bir belgenin terimlerini daha iyi degerlendirebiliriz Her terim o kavramin o belge icin onemini ifade eden belirli bir sozluk zincirindeki bir kavram olarak tanimlanabilir En cok alinan 5 belgenin ortalama Paice ve P norm a gore iyilestirildigini bildiriyorlar Zadrozny bulanik bilgi alma modelini yeniden ele aldi Ayrica bulanik genisletilmis Boole modelini su sekilde genisletiyor dilsel terimlerin anahtar kelimelerin onem agirliklari olarak varsayilmasi da belgelerde belgelerin ve sorgularin temsiline iliskin belirsizligi dikkate alarak Belgelerin ve sorgularin temsilindeki dilsel terimlerin yorumlanmasi ve Zadeh in bulanik mantigi dilsel ifadelerin hesabi acisindan eslestirilmesi Onerilen modelin bazi pragmatik yonlerini ozellikle de belgeleri ve sorgulari dizinleme tekniklerini ele alma Onerilen model metinsel bilginin gosterimi ve geri cagrilmasiyla ilgili hem belirsizlik hem de belirsizliklerin kavranmasini mumkun kilmaktadir Ayrica bakiniz span Bilgi alma Daha fazla okuma span S Betrabet M Koushik W Lee 1992 Information Retrieval Algorithms and Data structures Extended Boolean model Prentice Hall Inc 28 Eylul 2013 tarihinde kaynagindan arsivlendi9 Eylul 2017 Birden fazla yazar name list parameters kullanildi yardim ad ve soyadi eksik yardim Referanslar span Fox E A S Sharat 1986 A Comparison of Two Methods for Soft Boolean Interpretation in Information Retrieval Technical Report TR 86 1 Virginia Tech Department of Computer Science a b c Lee W C E A Fox 1988 Experimental Comparison of Schemes for Interpreting Boolean Queries Paice C D 1984 Soft Evaluation of Boolean Search Queries in Information Retrieval Systems Information Technology Res Dev Applications 3 1 33 42 Kang Bo Yeong Dae Won Kim Hae Jung Kim 2005 Fuzzy Information Retrieval Indexed by Concept Identification Text Speech and Dialogue Lecture Notes in Computer Science 3658 Springer Berlin Heidelberg ss 179 186 doi 10 1007 11551874 23 ISBN 978 3 540 28789 6 Zadrozny Slawomir Nowacka Katarzyna 2009 Fuzzy information retrieval model revisited Fuzzy Sets and Systems Elsevier North Holland Inc 160 15 ss 2173 2191 doi 10 1016 j fss 2009 02 012 Gizli kategoriler Oksuz maddeler Nisan 2025KB1 hatalari gereksiz parametreKB1 hatalari yazar veya editoru eksik