 Azərbaycanca
Azərbaycanca Deutsch
Deutsch 日本語
日本語 Lietuvos
Lietuvos සිංහල
සිංහල Türkçe
Türkçe Українська
Українська United State
United State
Bu maddede birçok sorun bulunmaktadır. Lütfen sayfayı geliştirin veya bu sorunlar konusunda bir yorum yapın.
|
Bu madde, ; zira herhangi bir maddeden bu maddeye verilmiş bir bağlantı yoktur. (Nisan 2025) |
Gizli anlamsal analiz ( LSA ), doğal dil işlemede, özellikle , bir dizi belge ve içerdikleri terimler arasındaki ilişkileri, belgeler ve terimlerle ilgili bir dizi kavram üreterek analiz eden bir tekniktir. LSA, anlamca yakın olan kelimelerin benzer metin parçalarında bulunacağını varsayar ( ). Büyük bir metin parçasından, belge başına kelime sayılarını içeren bir matris (satırlar benzersiz kelimeleri, sütunlar ise her bir belgeyi temsil eder) oluşturulur ve sütunlar arasındaki benzerlik yapısını korurken satır sayısını azaltmak için (SVD) adı verilen bir matematiksel teknik kullanılır. Daha sonra belgeler herhangi iki sütun arasındaki göre karşılaştırılır. 1'e yakın değerler çok benzer belgeleri temsil ederken 0'a yakın değerler çok farklı belgeleri temsil eder.
Gizli anlamsal yapıyı kullanan bir bilgi alma tekniği 1988'de , , , , , ve tarafından patentlendi.Bilgi almaya uygulanması bağlamında, bazen gizli anlamsal indeksleme ( LSI ) olarak adlandırılır.
Genel bakış
Oluşum matrisi
LSA, belgelerdeki terimlerin oluşumlarını tanımlayan bir belge-terim matrisi kullanabilir; bu, satırları terimlere ve sütunları belgelere karşılık gelen . Matrisin öğelerinin ağırlıklandırılmasının tipik bir örneği tf-idf'dir (terim sıklığı-ters belge sıklığı): Matrisin bir öğesinin ağırlığı, terimlerin her bir belgede göründüğü sayıyla orantılıdır; nadir terimler, göreceli önemlerini yansıtacak şekilde ağırlıklandırılır.
Bu matris, standart semantik modellerde de yaygındır, ancak matrislerin matematiksel özellikleri her zaman kullanılmadığından, mutlaka açıkça bir matris olarak ifade edilmesi gerekmez.
Rütbe düşürme
Oluşum matrisinin oluşturulmasından sonra LSA, terim-belge matrisine bulur. Bu yaklaşımların çeşitli nedenleri olabilir:
- Orijinal terim-belge matrisinin hesaplama kaynakları için çok büyük olduğu varsayılır; bu durumda, yaklaşık düşük rütbeli matris bir yaklaşım (bir "en az ve gerekli kötülük") olarak yorumlanır.
- Orijinal terim-belge matrisinin gürültülü olduğu varsayılır: örneğin, terimlerin anekdot niteliğindeki örnekleri elenecektir. Bu bakış açısından bakıldığında, yaklaşık matris, gürültüsüzleştirilmiş bir matris (orijinalinden daha iyi bir matris) olarak yorumlanır.
- Orijinal terim-belge matrisinin "gerçek" terim-belge matrisine kıyasla aşırı varsayılmaktadır. Yani, orijinal matris yalnızca her belgede gerçekten bulunan kelimeleri listeler, oysa biz her belgeyle ilişkili tüm kelimelerle ilgileniyor olabiliriz; bu genellikle eşanlamlılık nedeniyle çok daha büyük bir kümedir.
{(araba), (kamyon), (çiçek)} → {(1.3452 * araba + 0.2828 * kamyon), (çiçek)}
Bu, eş anlamlılığı belirleme sorununu hafifletir, çünkü sıralamanın düşürülmesinin benzer anlamlara sahip terimlerle ilişkili boyutları birleştirmesi beklenir. Aynı zamanda, çok anlamlı sözcüklerin "doğru" yöne işaret eden bileşenleri, benzer bir anlamı paylaşan sözcüklerin bileşenlerine eklendiğinden, sorununu da kısmen hafifletir. Buna karşılık, diğer yönlere işaret eden bileşenler ya basitçe birbirlerini iptal etme eğilimindedir ya da en kötüsü, amaçlanan yöne karşılık gelen yönlerdeki bileşenlerden daha küçük olma eğilimindedir.
Türetme
İzin vermek elemanın bulunduğu bir matris olsun terimin oluşumunu açıklar belgede (örneğin bu, frekans olabilir). şöyle görünecek:
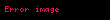
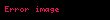
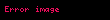
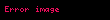
Şimdi bu matristeki bir satır, her bir belgeye ilişkin ilişkisini veren bir terime karşılık gelen bir vektör olacaktır:
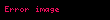
Benzer şekilde, bu matristeki bir sütun, her terime olan ilişkisini veren bir belgeye karşılık gelen bir vektör olacaktır:
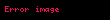
Şimdi nokta çarpımı İki terim vektörü arasındaki korelasyon, belgeler kümesi üzerindeki terimler arasındaki korelasyonu verir. Matris ürünü tüm bu nokta ürünlerini içerir. Öğe (elemana eşit olan) ) nokta çarpımını içerir ( ). Benzer şekilde matris tüm belge vektörleri arasındaki nokta ürünlerini içerir ve terimler üzerindeki korelasyonlarını verir: .
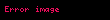
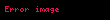
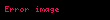
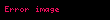
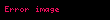
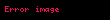

Şimdi, doğrusal cebir teorisinden, bir ayrıştırma vardır öyle ki Ve ve diyagonal bir matristir . Buna (SVD) denir:

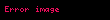
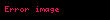
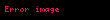
Bize terim ve belge korelasyonlarını veren matris ürünleri daha sonra şu hale gelir:
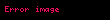
O zamandan beri Ve köşegen olduğunu görüyoruz özvektörleri içermelidir , sırasında özvektörleri olmalı . Her iki ürünün de sıfır olmayan girişleri tarafından verilen aynı sıfır olmayan öz değerleri vardır. veya eşit olarak, sıfır olmayan girdilerle . Şimdi ayrıştırma şu şekilde görünüyor:
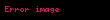
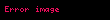
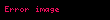
Değerler tekil değerler olarak adlandırılır ve Ve sol ve sağ tekil vektörler. Tek bir parçaya dikkat edin katkıda bulunan odur sıra. Bu satır vektörünün adının şu olmasına izin verin: . Benzer şekilde, tek kısmı katkıda bulunan odur kolon, . Bunlar özvektörler değildir, fakat tüm özvektörlere bağlıdırlar .
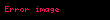
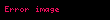
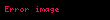
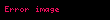
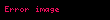
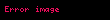
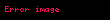
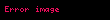
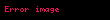
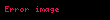
Seçtiğinizde ortaya çıkıyor ki en büyük tekil değerler ve bunlara karşılık gelen tekil vektörler Ve , rütbeyi alırsın yaklaşıklık en küçük hata ile ( ). Bu yaklaşımın çok az bir hatası vardır. Ama daha da önemlisi, artık terim ve belge vektörlerini bir "anlamsal uzay" olarak ele alabiliriz. Satır "terim" vektörü sonra sahip oldu onu daha düşük boyutlu bir uzaya eşleyen girdiler. Bu yeni boyutların anlaşılır hiçbir kavrama ilişkinliği yoktur. Bunlar, yüksek boyutlu uzayın düşük boyutlu bir yaklaşımıdır. Benzer şekilde, "belge" vektörü bu düşük boyutlu uzayda bir yaklaşımdır. Bu yaklaşımı şu şekilde yazıyoruz:
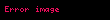
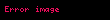
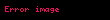
- Artık şunları yapabilirsiniz:
- İlgili belgelerin nasıl olduğunu görün Ve vektörleri karşılaştırarak düşük boyutlu uzaydadır Ve (genellikle ile).
- Terimleri karşılaştırma Ve vektörleri karşılaştırarak Ve . Dikkat artık bir sütun vektörüdür.
- Belgeler ve terim vektör gösterimleri, kosinüs gibi benzerlik ölçütlerini kullanarak k-ortalamalar gibi geleneksel kümeleme algoritmaları kullanılarak kümelenebilir.
- Bir sorgu verildiğinde, bunu mini bir belge olarak görüntüleyin ve düşük boyutlu uzaydaki belgelerinizle karşılaştırın.
İkincisini yapmak için öncelikle sorgunuzu düşük boyutlu uzaya çevirmeniz gerekir. Bu durumda belgelerinizde kullandığınız dönüşümün aynısını kullanmanız gerektiği sezgiseldir:
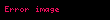
Burada diyagonal matrisin tersinin olduğunu unutmayın matris içindeki sıfırdan farklı her değerin ters çevrilmesiyle bulunabilir.
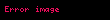
Bu, bir sorgu vektörünüz varsa şu anlama gelir: , çeviriyi sen yapmalısın Düşük boyutlu uzaydaki belge vektörleriyle karşılaştırmadan önce. Aynısını sözde terim vektörleri için de yapabilirsiniz:
t
Uygulamalar Yeni düşük boyutlu uzay genellikle şu amaçlar için kullanılabilir:
- Düşük boyutlu uzaydaki belgeleri karşılaştırın ( veri kümelemesi, belge sınıflandırması ).
- Çevrilmiş belgelerin temel kümesini analiz ettikten sonra, diller arasında benzer belgeleri bulun ( diller arası bilgi alma ).
- Terimler arasındaki ilişkileri bulun ( eş anlamlılık ve ).
- Verilen bir terim sorgusunu düşük boyutlu uzaya çevir ve eşleşen belgeleri bul ( bilgi alma ).
- Örneğin çoktan seçmeli sorularda MCQ cevaplama modelinde olduğu gibi, küçük terim grupları arasında anlamsal bir şekilde (yani bir bilgi gövdesi bağlamında) en iyi benzerliği bulun.
- Makine öğrenimi/metin madenciliği sistemlerinin özellik alanını genişletin
- Metin gövdesindeki kelime ilişkisini analiz edin
Eş anlamlılık ve çok anlamlılık doğal dil işlemedeki temel problemlerdir:
- Eş anlamlılık, aynı düşünceyi farklı sözcüklerle anlatmaktır. Bu nedenle, arama motorunda yapılan bir sorgu, sorguda görünen kelimeleri içermeyen ilgili bir belgeye ulaşmayı başaramayabilir. Örneğin, "doktorlar" için yapılan bir arama, kelimeler aynı anlama gelse bile " hekimler " kelimesini içeren bir belge döndürmeyebilir.
- Çok anlamlılık, aynı kelimenin birden fazla anlama gelmesi durumudur. Bu nedenle arama sonucunda, aranan kelimelerin yanlış anlamlarını içeren alakasız belgelere ulaşılabilmektedir. Örneğin, "ağaç" kelimesini arayan bir botanikçi ile bir bilgisayar bilimci muhtemelen farklı belge kümeleri isteyecektir.
Ticari uygulamalar
LSA, patentler için araştırmalarının yapılmasına yardımcı olmak için kullanılmıştır.
İnsan hafızasındaki uygulamalar
Gizli Anlamsal Analizin insan belleğinin incelenmesinde, özellikle serbest hatırlama ve bellek arama alanlarında kullanımı yaygınlaşmıştır. İki kelimenin semantik benzerliği (LSA ile ölçüldüğü gibi) ile kelimelerin rastgele ortak isimlerden oluşan çalışma listelerinin kullanıldığı serbest hatırlama görevlerinde birbiri ardına hatırlanma olasılığı arasında pozitif bir korelasyon vardır. Ayrıca bu durumlarda benzer kelimeler arasındaki yanıtlar arası sürenin, farklı kelimeler arasındaki yanıtlara göre çok daha hızlı olduğunu da kaydettiler. Bu bulgulara adı verilir.
Katılımcılar çalışılan öğeleri hatırlarken hata yaptıklarında, bu hataların daha çok istenen öğeyle anlamsal olarak daha ilişkili olan ve daha önce çalışılmış bir listede bulunan öğeler olma eğilimi gösterdiği görüldü. Bu tür önceki liste ihlalleri, artık çağrıldıkları gibi, geri çağırma için geçerli listedeki öğelerle rekabet ediyor gibi görünüyor.
(WAS) adı verilen başka bir model de bir dizi deneyden serbest ilişkilendirme verileri toplayarak hafıza çalışmalarında kullanılır ve 72.000'den fazla farklı kelime çifti için kelime ilişkisi ölçümlerini içerir.
Uygulama
genellikle büyük matris yöntemleri (örneğin, ) kullanılarak hesaplanır ancak büyük, tam rütbeli matrisin bellekte tutulmasını gerektirmeyen bir sinir ağı benzeri yaklaşım yoluyla artımlı olarak ve büyük ölçüde azaltılmış kaynaklarla da hesaplanabilir. Hızlı, artımlı, düşük bellekli, büyük matrisli bir SVD algoritması geliştirildi. Bu hızlı algoritmaların MATLAB ve Python uygulamaları mevcuttur. Gorrell ve Webb'in (2005) stokastik yaklaşımının aksine, Brand'in algoritması (2003) kesin bir çözüm sunmaktadır. Son yıllarda SVD'nin hesaplama karmaşıklığını azaltmak için ilerleme kaydedildi; örneğin, paralel özdeğer ayrıştırması gerçekleştirmek için paralel bir ARPACK algoritması kullanılarak, karşılaştırılabilir tahmin kalitesi sağlanırken SVD hesaplama maliyetinin hızlandırılması mümkün oldu.
Sınırlamalar
LSA'nın bazı dezavantajları şunlardır:
Ortaya çıkan boyutların yorumlanması zor olabilir. Örneğin,
- {(araba), (kamyon), (çiçek)} ↦ {(1.3452 * araba + 0.2828 * kamyon), (çiçek)}
- (1.3452 * otomobil + 0.2828 * kamyon) bileşeni "araç" olarak yorumlanabilir. Ancak, vakaların yakın olması çok olasıdır
- {(araba), (şişe), (çiçek)} ↦ {(1.3452 * araba + 0.2828 * şişe ), (çiçek)}
- gerçekleşecektir. Bu, matematiksel düzeyde gerekçelendirilebilen, ancak doğal dilde hemen belirgin bir anlamı olmayan sonuçlara yol açar. Yine de, (1.3452 * araba + 0.2828 * şişe) bileşeni haklı görülebilir çünkü hem şişeler hem de arabalar şeffaf ve opak parçalara sahiptir, insan yapımıdır ve yüksek olasılıkla yüzeylerinde logolar/kelimeler bulunur; dolayısıyla, birçok yönden bu iki kavram "anlamsal olarak aynıdır." Yani, söz konusu bir dil içinde, atanacak kolayca bulunabilen bir kelime olmayabilir ve açıklanabilirlik, basit kelime/sınıf/kavram atama görevi yerine bir analiz görevi haline gelir.
- LSA, (yani bir kelimenin birden fazla anlamını) yalnızca kısmen yakalayabilir çünkü bir kelimenin her bir kullanımı, kelime uzayda tek bir nokta olarak temsil edildiği için aynı anlama sahipmiş gibi ele alınır. Örneğin, “Yönetim Kurulu Başkanı” ifadesini içeren bir belgede “başkan” kelimesinin geçmesi ile “başkan yapımcısı” ifadesini içeren ayrı bir belgede “başkan” kelimesinin geçmesi aynı kabul edilir. Bu davranış, vektör gösteriminin, gövdedeki tüm kelimelerin farklı anlamlarının ortalaması olmasıyla sonuçlanıyor ve bu da karşılaştırmayı zorlaştırabiliyor. Ancak, sözcüklerin bir metin boyunca sahip olması (yani tüm anlamların eşit derecede olası olmaması) nedeniyle etki genellikle azalır.
- Bir metnin sıralanmamış bir kelime koleksiyonu olarak gösterildiği kelime torbası modelinin (BOW) sınırlamaları. Kelime torbası modeli (BOW) sınırlamalarından bazılarını ele almak için, terimler arasında doğrudan ve dolaylı ilişkilerin yanı sıra bulmak için çoklu gram sözlüğü kullanılabilir.
- LSA'nın olasılıksal modeli gözlemlenen verilerle uyuşmuyor: LSA, kelimelerin ve belgelerin ortak bir Gauss modeli oluşturduğunu varsayar ( ergodik hipotez ), oysa bir Poisson dağılımı gözlemlenmiştir. Bu nedenle, standart LSA'dan daha iyi sonuçlar verdiği bildirilen, çok terimli bir modele dayanan daha yeni bir alternatiftir.
Alternatif yöntemler
Anlamsal karma
Anlamsal karma işleminde belgeler, anlamsal olarak benzer belgelerin yakın adreslerde yer alması için bir sinir ağı aracılığıyla bellek adreslerine eşlenir. Derin sinir ağı esas olarak büyük bir belge kümesinden elde edilen kelime sayısı vektörlerinin oluşturur. Sorgu belgesine benzeyen belgeler, sorgu belgesinin adresinden yalnızca birkaç bit farklı olan tüm adreslere erişilerek bulunabilir. Karma kodlamanın verimliliğini yaklaşık eşleşmeye genişletmenin bu yolu, şu anda en hızlı yöntem olan çok daha hızlıdır. [ ]
Gizli anlamsal dizinleme
Gizli anlamsal dizinleme ( LSI ), yapılandırılmamış bir metin koleksiyonunda yer alan terimler ve kavramlar arasındaki ilişkilerdeki kalıpları belirlemek için (SVD) adı verilen bir matematiksel teknik kullanan bir dizinleme ve alma yöntemidir. LSI, aynı bağlamlarda kullanılan sözcüklerin benzer anlamlara sahip olma eğiliminde olduğu ilkesine dayanır. LSI'nin temel bir özelliği, benzer bağlamlarda geçen terimler arasında ilişkiler kurarak bir kavramsal içeriğini çıkarma yeteneğidir.
LSI aynı zamanda, tarafından 1970'lerin başında geliştirilen çok değişkenli bir istatistiksel teknik olan , belgelerdeki kelime sayımlarından oluşturulan bir uygulanmasıdır.
Bir metin koleksiyonunda latent olan semantically ilişkili terimleri ilişkilendirme yeteneği nedeniyle " latent semantic indeksleme" olarak adlandırılan bu yöntem, ilk olarak 1980'lerin sonlarında metinlere uygulandı. Gizli anlam analizi (LSA) olarak da adlandırılan bu yöntem, bir metindeki kelimelerin kullanımında altta yatan gizli anlamsal yapıyı ortaya çıkarır ve bunun, kullanıcı sorgularına yanıt olarak metnin anlamını çıkarmak için nasıl kullanılabileceğini, yaygın olarak kavram aramaları olarak adlandırılır. LSI'dan geçmiş bir belge kümesine yönelik sorgular veya kavram aramaları, arama ölçütleriyle belirli bir kelime veya kelimeleri paylaşmasa bile, arama ölçütleriyle anlam bakımından kavramsal olarak benzer sonuçlar döndürecektir.
LSI'nin faydaları
LSI ve vektör uzayı modellerinin en sorunlu kısıtlamalarından biri olan geri çağırmayı artırarak eşanlamlılığın üstesinden gelmeye yardımcı olur. Eş anlamlılık, çoğu zaman belge yazarları ile bilgi arama sistemlerinin kullanıcıları tarafından kullanılan kelime dağarcığındaki uyumsuzlukların nedenidir. Sonuç olarak, Boole veya anahtar sözcük sorguları genellikle alakasız sonuçlar döndürür ve alakalı bilgileri kaçırır.
LSI aynı zamanda otomatik belge kategorizasyonu gerçekleştirmek için de kullanılır. Aslında, birçok deney LSI ile insanların metni işleme ve kategorize etme biçimleri arasında bir dizi korelasyon olduğunu göstermiştir. Belge kategorizasyonu, belgelerin kategorilerin kavramsal içeriğine benzerliklerine göre bir veya daha fazla önceden tanımlanmış kategoriye atanmasıdır. LSI, her kategori için kavramsal temeli oluşturmak amacıyla örnek belgeler kullanır. Kategorizasyon işlemi sırasında, kategorilendirilen dokümanlarda yer alan kavramlar, örnek öğelerde yer alan kavramlarla karşılaştırılır ve içerdikleri kavramlar ile örnek dokümanlarda yer alan kavramlar arasındaki benzerliklere göre dokümanlara bir veya birden fazla kategori atanır.
LSI kullanılarak belgelerin kavramsal içeriğine dayalı dinamik kümeleme de gerçekleştirilebilir. Kümeleme, her kümenin kavramsal temelini oluşturmak için örnek belgeler kullanılmadan, belgeleri kavramsal benzerliklerine göre gruplandırmanın bir yoludur. Bu, yapılandırılmamış metinlerden oluşan bilinmeyen bir koleksiyonla uğraşırken çok faydalıdır.
LSI, tamamen matematiksel bir yaklaşım kullandığı için dilden bağımsızdır. Bu, LSI'ın sözlük ve eş anlamlılar sözlüğü gibi yardımcı yapıların kullanımına ihtiyaç duymadan herhangi bir dilde yazılmış bilginin anlamsal içeriğini ortaya çıkarmasını sağlar. LSI aynı zamanda diller arası ve örnek tabanlı kategorizasyon da gerçekleştirebilir. Örneğin, sorgular tek bir dilde, örneğin İngilizce'de yapılabilir ve tamamen farklı bir dilden veya birden fazla dilden oluşsa bile kavramsal olarak benzer sonuçlar döndürülür.[][ ]
LSI yalnızca kelimelerle çalışmakla sınırlı değildir. Ayrıca, keyfi karakter dizilerini de işleyebilir. Metin olarak ifade edilebilen herhangi bir nesne LSI vektör uzayında temsil edilebilir. Örneğin, MEDLINE özetleriyle yapılan testler, LSI'nin MEDLINE atıflarının başlıklarında ve özetlerinde yer alan biyolojik bilgilerin kavramsal modellemesine dayalı olarak genleri etkili bir şekilde sınıflandırabildiğini göstermiştir.
LSI, yeni ve değişen terminolojiye otomatik olarak uyum sağlar ve gürültüye (yani yanlış yazılmış kelimeler, tipografik hatalar, okunamayan karakterler, vb.) karşı çok toleranslı olduğu gösterilmiştir. Bu, özellikle Optik Karakter Tanıma (OCR) ve konuşmadan metne dönüştürme yoluyla türetilen metinleri kullanan uygulamalar için önemlidir. LSI aynı zamanda seyrek, belirsiz ve çelişkili verilerle de etkili bir şekilde başa çıkar.
LSI'nin etkili olabilmesi için metnin cümle biçiminde olması gerekmez. Listeler, serbest biçimli notlar, e-posta, web tabanlı içerik vb. ile çalışabilir. Bir metin koleksiyonu birden fazla terim içerdiği sürece, LSI metinde yer alan önemli terimler ve kavramlar arasındaki ilişkilerdeki kalıpları belirlemek için kullanılabilir.
LSI, bir dizi kavramsal eşleştirme sorununa yararlı bir çözüm olduğunu kanıtladı. Bu tekniğin, nedensel, hedef odaklı ve taksonomik bilgiler de dahil olmak üzere temel ilişki bilgilerini yakaladığı gösterilmiştir.
LSI zaman çizelgesi
- 1960'ların ortası – Faktör analizi tekniği ilk kez tanımlandı ve test edildi (H. Borko ve M. Bernick)
- 1988 – LSI tekniği hakkında öncü makale yayınlandı
- 1989 – Orijinal patent verildi
- 1992 – Makaleleri gözden geçirenlere atamak için LSI'nin ilk kullanımı
- 1994 – LSI’nin diller arası uygulanması için patent verildi (Landauer ve ark.)
- 1995 – LSI'nin denemeleri notlandırmak için ilk kullanımı (Foltz ve diğerleri, Landauer ve diğerleri)
- 1999 – Yapılandırılmamış metinlerin ( ) analizi için istihbarat topluluğuna yönelik LSI teknolojisinin ilk uygulaması.
- 2002 – İstihbarat tabanlı devlet kurumlarına (SAIC) LSI tabanlı ürün teklifi
LSI'nin Matematiği
LSI, bir metin koleksiyonundaki kavramsal ilişkileri öğrenmek için yaygın doğrusal cebir tekniklerini kullanır. Genel olarak süreç, ağırlıklı bir terim-belge matrisi oluşturmayı, matris üzerinde yapmayı ve matrisi kullanarak metinde yer alan kavramları belirlemeyi içerir.
LSI, bir terim-belge matrisi oluşturarak başlar, , olayların meydana gelişini tespit etmek için bir koleksiyon içindeki benzersiz terimler belgeler. Bir terim-belge matrisinde, her terim bir satırla ve her belge bir sütunla temsil edilir; her matris hücresi, , başlangıçta ilişkili terimin belirtilen belgede göründüğü zaman sayısını temsil eder, . Bu matris genellikle çok büyük ve çok seyrektir.


Bir terim-belge matrisi oluşturulduktan sonra, verileri koşullandırmak için ona yerel ve küresel ağırlıklandırma fonksiyonları uygulanabilir. Ağırlıklandırma fonksiyonları her hücreyi dönüştürür, ile ilgili , yerel bir terim ağırlığının ürünü olmak üzere, , bir terimin bir belgedeki göreceli sıklığını ve genel bir ağırlığı tanımlayan, Bu terim, tüm belge koleksiyonunda terimin göreceli sıklığını açıklar.
Bazı yaygın yerel ağırlıklandırma fonksiyonları aşağıdaki tabloda tanımlanmıştır.
| İkili | eğer terim belgede mevcutsa, yoksa | |
| TerimFrekans | , terimin ortaya çıkış sayısı belgede | |
| Kayıt | ||
| Augnorm |
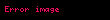
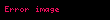
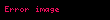
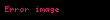
Aşağıdaki tabloda bazı yaygın küresel ağırlıklandırma fonksiyonları tanımlanmıştır.
| İkili | ||
| Normal | ||
| GfIdf | , Neresi terimin toplam sayısıdır tüm koleksiyonda bulunur ve terimdeki belge sayısıdır meydana gelmek. | |
| Entropi | , Neresi |

LSI ile yapılan deneysel çalışmalar, Log ve Entropi ağırlıklandırma fonksiyonlarının pratikte birçok veri kümesiyle iyi çalıştığını bildirmektedir. Başka bir deyişle, her giriş ile ilgili şu şekilde hesaplanır:
Sıralama düşürülmüş tekil değer ayrıştırması
Metinde yer alan terimler ve kavramlar arasındaki ilişkilerdeki örüntüleri belirlemek için matris üzerinde rütbesi düşürülmüş yapılır. SVD, LSI'nin temelini oluşturur. Tek terim-frekans matrisini yaklaştırarak terim ve belge vektör uzaylarını hesaplar, , üç başka matrise—bir m by r terim-kavram vektör matrisi , r'ye r tekil değerler matrisi ve n by r kavram-belge vektör matrisi, Aşağıdaki ilişkileri sağlayan:
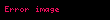
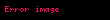
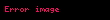
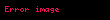
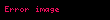
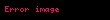
Formülde, A, bir metin koleksiyonundaki terim frekanslarının m x n ağırlıklı matrisidir; burada m benzersiz terim sayısı ve n belge sayısıdır. T, r'nin A'nın rütbesi olduğu ve benzersiz boyutlarının bir ölçüsü olan terim vektörlerinin m x r matrisinin hesaplanmasıdır. S, azalan tekil değerlerden oluşan r x r boyutlu bir köşegen matrisidir ve D, belge vektörlerinden oluşan n x r boyutlu bir matristir.
Daha sonra SVD, yalnızca en büyük k « tutularak sıralamayı azaltmak için k tipik olarak 100 ila 300 boyutlarında olan tekil değer matrisi S'deki r köşegen girişi. Bu, terim ve belge vektör matrisi boyutlarını sırasıyla m x k ve n x k'ye etkili bir şekilde azaltır. SVD işlemi, bu indirgemeyle birlikte, A'nın orijinal uzayındaki gürültüyü ve diğer istenmeyen eserleri azaltırken metindeki en önemli anlamsal bilgiyi koruma etkisine sahiptir. Bu indirgenmiş matris kümesi genellikle şu şekilde değiştirilmiş bir formülle gösterilir:
- A ≈ A k = T k S k D kT
Verimli LSI algoritmaları tam bir SVD hesaplayıp sonra onu kesmek yerine sadece ilk k tekil değeri ve terim ve belge vektörlerini hesaplar.
Bu rütbe indirgemesinin esasen A matrisi üzerinde Temel Bileşen Analizi (PCA) yapmakla aynı olduğunu, ancak PCA'nın ortalamaları çıkardığını unutmayın. PCA, A matrisinin seyrekliğini kaybeder, bu da onu büyük sözlükler için uygulanamaz hale getirebilir.
LSI vektör uzaylarını sorgulama ve genişletme
Hesaplanan T k ve D k matrisleri, belge koleksiyonundan türetilen kavramsal bilgileri içeren, hesaplanan tekil değerler S k ile terim ve belge vektör uzaylarını tanımlar. Bu uzaylardaki terimlerin veya belgelerin benzerliği, bunların bu uzaylarda birbirlerine ne kadar yakın olduklarının bir faktörüdür ve genellikle karşılık gelen vektörler arasındaki açının bir fonksiyonu olarak hesaplanır.
Mevcut bir LSI dizininin belge alanında sorguların ve yeni belgelerin metinlerini temsil eden vektörleri bulmak için aynı adımlar kullanılır. A = TSD T denkleminin eşdeğer D = A T TS −1 denklemine basit bir dönüşümüyle, A'da yeni bir sütun hesaplanıp ardından yeni sütun TS −1 ile çarpılarak bir sorgu veya yeni bir belge için yeni bir vektör d oluşturulabilir. A'daki yeni sütun, başlangıçta türetilen genel terim ağırlıkları kullanılarak hesaplanır ve aynı yerel ağırlıklandırma işlevi sorgudaki veya yeni belgedeki terimlere uygulanır.
Bu şekilde vektör hesaplamanın bir dezavantajı, yeni aranabilir belgeler eklerken, orijinal endeks için SVD aşamasında bilinmeyen terimlerin göz ardı edilmesidir. Bu terimlerin, orijinal metin koleksiyonundan türetilen küresel ağırlıklar ve öğrenilen korelasyonlar üzerinde hiçbir etkisi olmayacaktır. Ancak yeni metin için hesaplanan vektörler, diğer tüm belge vektörleriyle benzerlik karşılaştırmaları için hâlâ çok önemlidir.
Bu şekilde bir LSI indeksi için belge vektör uzaylarının yeni belgelerle genişletilmesi işlemine katlama denir. Katlama işlemi yeni metnin yeni anlamsal içeriğini hesaba katmasa da, bu şekilde önemli sayıda belge eklemek, içerdikleri terimler ve kavramlar eklendikleri LSI dizininde iyi bir şekilde temsil edildiği sürece sorgular için yine de iyi sonuçlar sağlayacaktır. Yeni bir belge kümesinin terimleri ve kavramlarının bir LSI dizinine dahil edilmesi gerektiğinde, terim-belge matrisi ve SVD yeniden hesaplanmalı veya artımlı bir güncelleme yöntemine (örneğin de açıklanan yönteme) ihtiyaç duyulur.
LSI'nin ek kullanımları
Modern bilgi arama sistemleri için metinle anlamsal bir temelde çalışabilme yeteneğinin önemli olduğu genel olarak kabul edilmektedir. Sonuç olarak, ölçeklenebilirlik ve performanstaki önceki zorlukların üstesinden gelinmesiyle birlikte LSI kullanımı son yıllarda önemli ölçüde genişledi.
LSI, çeşitli bilgi alma ve metin işleme uygulamalarında kullanılıyor, ancak birincil uygulaması kavram arama ve otomatik belge kategorizasyonu olmuştur. LSI'nin kullanıldığı diğer bazı yollar aşağıda listelenmiştir:
- Bilgi keşfi ( , Hükümet/İstihbarat topluluğu, Yayıncılık)
- Otomatik belge sınıflandırması (eKeşif, Hükümet/İstihbarat topluluğu, Yayıncılık)
- Metin özetleme (eKeşif, Yayıncılık)
- İlişki keşfi (Hükümet, İstihbarat topluluğu, Sosyal Ağlar)
- Bireylerin ve kuruluşların bağlantı çizelgelerinin otomatik olarak oluşturulması (Hükümet, İstihbarat topluluğu)
- Teknik makalelerin ve hibelerin gözden geçirenlerle eşleştirilmesi (Hükümet)
- Çevrimiçi müşteri desteği (Müşteri Yönetimi)
- Belge yazarlığının belirlenmesi (Eğitim)
- Görüntülerin otomatik anahtar kelime açıklaması
- Yazılım kaynak kodunun anlaşılması (Yazılım Mühendisliği)
- Spam filtreleme (Sistem Yönetimi)
- Bilgi görselleştirme
- (Eğitim)
- Hisse senedi getirisi tahmini
- Rüya İçeriği Analizi (Psikoloji)
LSI, işletmelerin dava süreçlerine hazırlanmasına yardımcı olmak amacıyla elektronik belge keşfi (eKeşif) amacıyla giderek daha fazla kullanılıyor. eKeşifte, büyük yapılandırılmamış metin koleksiyonlarını kavramsal bir temele göre kümeleme, kategorilere ayırma ve arama yeteneği esastır. LSI kullanılarak yapılan kavram tabanlı arama, önde gelen sağlayıcılar tarafından 2003 yılı gibi erken bir tarihte eKeşif sürecine uygulanmıştır.
LSI'ye Yönelik Zorluklar
LSI'a yönelik ilk zorluklar ölçeklenebilirlik ve performansa odaklanmıştı. LSI, diğer bilgi alma tekniklerine kıyasla nispeten yüksek hesaplama performansı ve bellek gerektirir. Ancak modern yüksek hızlı işlemcilerin kullanılmaya başlanması ve ucuz belleklerin bulunmasıyla bu hususlar büyük ölçüde ortadan kalktı. Bazı LSI uygulamalarında, matris ve SVD hesaplamaları yoluyla tamamen işlenmiş 30 milyondan fazla belgeyi içeren gerçek dünya uygulamaları yaygındır. LSI'nin tamamen ölçeklenebilir (sınırsız sayıda belge, çevrimiçi eğitim) bir uygulaması, açık kaynaklı yazılım paketinde yer almaktadır.
LSI'daki bir diğer zorluk ise SVD'yi gerçekleştirmek için kullanılacak optimum boyut sayısının belirlenmesindeki iddia edilen zorluktur. Genel bir kural olarak, daha az boyut, bir metin koleksiyonunda yer alan kavramların daha geniş karşılaştırmalarına olanak tanırken, daha fazla boyut, kavramların daha spesifik (veya daha alakalı) karşılaştırmalarına olanak tanır. Kullanılabilecek gerçek boyut sayısı koleksiyondaki belge sayısıyla sınırlıdır. Araştırmalar, orta büyüklükteki belge koleksiyonları (yüz binlerce belge) için genellikle yaklaşık 300 boyutun ve daha büyük belge koleksiyonları (milyonlarca belge) için belki de 400 boyutun en iyi sonuçları sağlayacağını göstermiştir. Ancak son araştırmalar, belge koleksiyonunun boyutuna ve doğasına bağlı olarak 50-1000 boyutun uygun olduğunu göstermektedir. LSI için, PCA veya benzer şekilde, korunan varyans oranını kontrol ederek optimum boyutluluğu belirlemek uygun değildir. Eş anlamlılık testi veya eksik kelimelerin tahmini, doğru boyutluluğu bulmanın iki olası yöntemidir. LSI konuları denetimli öğrenme yöntemlerinde özellik olarak kullanıldığında, ideal boyutluluğu bulmak için tahmin hatası ölçümlerinden yararlanılabilir.
Ayrıca bakınız
Referanslar
- ↑ Susan T. Dumais (2005). "Latent Semantic Analysis". Annual Review of Information Science and Technology. 38: 188–230. doi:10.1002/aris.1440380105.
- ↑ "US Patent 4,839,853". Archived from the original on 2017-12-02. (now expired)
- ↑ "The Latent Semantic Indexing home page".
- ↑ "image". topicmodels.west.uni-koblenz.de. Archived from the original on 17 March 2023.
- ↑ Markovsky I. (2012) Low-Rank Approximation: Algorithms, Implementation, Applications, Springer, 2012, ISBN 978-1-4471-2226-5 [page needed]
- ↑ Alain Lifchitz; Sandra Jhean-Larose; Guy Denhière (2009). "Effect of tuned parameters on an LSA multiple choice questions answering model" (PDF). Behavior Research Methods. 41 (4): 1201–1209. arXiv:0811.0146. doi:10.3758/BRM.41.4.1201. PMID 19897829. S2CID 480826.
- 1 2 Ramiro H. Gálvez; Agustín Gravano (2017). "Assessing the usefulness of online message board mining in automatic stock prediction systems". Journal of Computational Science. 19: 1877–7503. doi:10.1016/j.jocs.2017.01.001. hdl:11336/60065.
- 1 2 Altszyler, E.; Ribeiro, S.; Sigman, M.; Fernández Slezak, D. (2017). "The interpretation of dream meaning: Resolving ambiguity using Latent Semantic Analysis in a small corpus of text". Consciousness and Cognition. 56: 178–187. arXiv:1610.01520. doi:10.1016/j.concog.2017.09.004. PMID 28943127. S2CID 195347873.
- ↑ Gerry J. Elman (October 2007). "Automated Patent Examination Support - A proposal". Biotechnology Law Report. 26 (5): 435–436. doi:10.1089/blr.2007.9896.
- ↑ Marc W. Howard; Michael J. Kahana (1999). "Contextual Variability and Serial Position Effects in Free Recall" (PDF). APA PsycNet Direct.
- ↑ Franklin M. Zaromb; et al. (2006). Temporal Associations and Prior-List Intrusions in Free Recall (PDF). Interspeech'2005.
- ↑ Nelson, Douglas. "The University of South Florida Word Association, Rhyme and Word Fragment Norms". Retrieved May 8, 2011.
- ↑ Geneviève Gorrell; Brandyn Webb (2005). "Generalized Hebbian Algorithm for Latent Semantic Analysis" (PDF). Interspeech'2005. Archived from the original (PDF) on 2008-12-21.
- 1 2 Matthew Brand (2006). "Fast Low-Rank Modifications of the Thin Singular Value Decomposition". Linear Algebra and Its Applications. 415: 20–30. doi:10.1016/j.laa.2005.07.021.
- ↑ "MATLAB". Archived from the original on 2014-02-28.
- ↑ Python
- ↑ Ding, Yaguang; Zhu, Guofeng; Cui, Chenyang; Zhou, Jian; Tao, Liang (2011). "A parallel implementation of Singular Value Decomposition based on Map-Reduce and PARPACK". Proceedings of 2011 International Conference on Computer Science and Network Technology. pp. 739–741. doi:10.1109/ICCSNT.2011.6182070. ISBN 978-1-4577-1587-7. S2CID 15281129.
- 1 2 Deerwester, Scott; Dumais, Susan T.; Furnas, George W.; Landauer, Thomas K.; Harshman, Richard (1990). "Indexing by latent semantic analysis". Journal of the American Society for Information Science. 41 (6): 391–407. CiteSeerX 10.1.1.108.8490. doi:10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9.
- ↑ Abedi, Vida; Yeasin, Mohammed; Zand, Ramin (27 November 2014). "Empirical study using network of semantically related associations in bridging the knowledge gap". Journal of Translational Medicine. 12 (1): 324. doi:10.1186/s12967-014-0324-9. PMC 4252998. PMID 25428570.
- ↑ Thomas Hofmann (1999). "Probabilistic Latent Semantic Analysis". Uncertainty in Artificial Intelligence. arXiv:1301.6705.
- ↑ Salakhutdinov, Ruslan, and Geoffrey Hinton. "Semantic hashing." RBM 500.3 (2007): 500.
- 1 2 3 Deerwester, S., et al, Improving Information Retrieval with Latent Semantic Indexing, Proceedings of the 51st Annual Meeting of the American Society for Information Science 25, 1988, pp. 36–40.
- ↑ Benzécri, J.-P. (1973). L'Analyse des Données. Volume II. L'Analyse des Correspondences. Paris, France: Dunod.
- ↑ Furnas, G. W.; Landauer, T. K.; Gomez, L. M.; Dumais, S. T. (1987). "The vocabulary problem in human-system communication". Communications of the ACM. 30 (11): 964–971. CiteSeerX 10.1.1.118.4768. doi:10.1145/32206.32212. S2CID 3002280.
- ↑ Landauer, T., et al., Learning Human-like Knowledge by Singular Value Decomposition: A Progress Report, M. I. Jordan, M. J. Kearns & S. A. Solla (Eds.), Advances in Neural Information Processing Systems 10, Cambridge: MIT Press, 1998, pp. 45–51.
- ↑ Dumais, S.; Platt, J.; Heckerman, D.; Sahami, M. (1998). "Inductive learning algorithms and representations for text categorization" (PDF). Proceedings of the seventh international conference on Information and knowledge management - CIKM '98. pp. 148. CiteSeerX 10.1.1.80.8909. doi:10.1145/288627.288651. ISBN 978-1581130614. S2CID 617436.
- ↑ Homayouni, R.; Heinrich, K.; Wei, L.; Berry, M. W. (2004). "Gene clustering by Latent Semantic Indexing of MEDLINE abstracts". Bioinformatics. 21 (1): 104–115. doi:10.1093/bioinformatics/bth464. PMID 15308538.
- ↑ Price, R. J.; Zukas, A. E. (2005). "Application of Latent Semantic Indexing to Processing of Noisy Text". Intelligence and Security Informatics. Lecture Notes in Computer Science. Vol. 3495. p. 602. doi:10.1007/11427995_68. ISBN 978-3-540-25999-2.
- ↑ Ding, C., A Similarity-based Probability Model for Latent Semantic Indexing, Proceedings of the 22nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 1999, pp. 59–65.
- ↑ Bartell, B., Cottrell, G., and Belew, R., Latent Semantic Indexing is an Optimal Special Case of Multidimensional Scaling[dead link], Proceedings, ACM SIGIR Conference on Research and Development in Information Retrieval, 1992, pp. 161–167.
- ↑ Graesser, A.; Karnavat, A. (2000). "Latent Semantic Analysis Captures Causal, Goal-oriented, and Taxonomic Structures". Proceedings of CogSci 2000: 184–189. CiteSeerX 10.1.1.23.5444.
- ↑ Dumais, S.; Nielsen, J. (1992). "Automating the assignment of submitted manuscripts to reviewers". Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval - SIGIR '92. pp. 233–244. CiteSeerX 10.1.1.16.9793. doi:10.1145/133160.133205. ISBN 978-0897915236. S2CID 15038631.
- ↑ Berry, M. W., and Browne, M., Understanding Search Engines: Mathematical Modeling and Text Retrieval, Society for Industrial and Applied Mathematics, Philadelphia, (2005).
- ↑ Landauer, T., et al., Handbook of Latent Semantic Analysis, Lawrence Erlbaum Associates, 2007.
- ↑ Berry, Michael W., Dumais, Susan T., O'Brien, Gavin W., Using Linear Algebra for Intelligent Information Retrieval, December 1994, SIAM Review 37:4 (1995), pp. 573–595.
- ↑ Dumais, S., Latent Semantic Analysis, ARIST Review of Information Science and Technology, vol. 38, 2004, Chapter 4.
- ↑ Best Practices Commentary on the Use of Search and Information Retrieval Methods in E-Discovery, the Sedona Conference, 2007, pp. 189–223.
- ↑ Foltz, P. W. and Dumais, S. T. Personalized Information Delivery: An analysis of information filtering methods, Communications of the ACM, 1992, 34(12), 51-60.
- ↑ Gong, Y., and Liu, X., Creating Generic Text Summaries, Proceedings, Sixth International Conference on Document Analysis and Recognition, 2001, pp. 903–907.
- ↑ Bradford, R., Efficient Discovery of New Information in Large Text Databases, Proceedings, IEEE International Conference on Intelligence and Security Informatics, Atlanta, Georgia, LNCS Vol. 3495, Springer, 2005, pp. 374–380.
- ↑ Bradford, R. B. (2006). "Application of Latent Semantic Indexing in Generating Graphs of Terrorist Networks". Intelligence and Security Informatics. Lecture Notes in Computer Science. Vol. 3975. pp. 674–675. doi:10.1007/11760146_84. ISBN 978-3-540-34478-0.
- ↑ Yarowsky, D., and Florian, R., Taking the Load off the Conference Chairs: Towards a Digital Paper-routing Assistant, Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in NLP and Very-Large Corpora, 1999, pp. 220–230.
- ↑ Caron, J., Applying LSA to Online Customer Support: A Trial Study, Unpublished Master's Thesis, May 2000.
- ↑ Soboroff, I., et al, Visualizing Document Authorship Using N-grams and Latent Semantic Indexing, Workshop on New Paradigms in Information Visualization and Manipulation, 1997, pp. 43–48.
- ↑ Monay, F., and Gatica-Perez, D., On Image Auto-annotation with Latent Space Models, Proceedings of the 11th ACM international conference on Multimedia, Berkeley, CA, 2003, pp. 275–278.
- ↑ Maletic, J.; Marcus, A. (November 13–15, 2000). "Using latent semantic analysis to identify similarities in source code to support program understanding". Proceedings 12th IEEE Internationals Conference on Tools with Artificial Intelligence. ICTAI 2000. pp. 46–53. CiteSeerX 10.1.1.36.6652. doi:10.1109/TAI.2000.889845. ISBN 978-0-7695-0909-9. S2CID 10354564.
- ↑ Gee, K., Using Latent Semantic Indexing to Filter Spam, in: Proceedings, 2003 ACM Symposium on Applied Computing, Melbourne, Florida, pp. 460–464.
- ↑ Landauer, T., Laham, D., and Derr, M., From Paragraph to Graph: Latent Semantic Analysis for Information Visualization, Proceedings of the National Academy of Sciences, 101, 2004, pp. 5214–5219.
- ↑ Foltz, Peter W., Laham, Darrell, and Landauer, Thomas K., Automated Essay Scoring: Applications to Educational Technology, Proceedings of EdMedia, 1999.
- ↑ Gordon, M., and Dumais, S., Using Latent Semantic Indexing for Literature Based Discovery, Journal of the American Society for Information Science, 49(8), 1998, pp. 674–685.
- ↑ There Has to be a Better Way to Search, 2008, White Paper, Fios, Inc.
- ↑ Karypis, G., Han, E., Fast Supervised Dimensionality Reduction Algorithm with Applications to Document Categorization and Retrieval, Proceedings of CIKM-00, 9th ACM Conference on Information and Knowledge Management.
- ↑ Radim Řehůřek (2011). "Subspace Tracking for Latent Semantic Analysis". Advances in Information Retrieval. Lecture Notes in Computer Science. Vol. 6611. pp. 289–300. doi:10.1007/978-3-642-20161-5_29. ISBN 978-3-642-20160-8.
- ↑ Bradford, R., An Empirical Study of Required Dimensionality for Large-scale Latent Semantic Indexing Applications, Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, California, USA, 2008, pp. 153–162.
- ↑ Landauer, Thomas K., and Dumais, Susan T., Latent Semantic Analysis, Scholarpedia, 3(11):4356, 2008.
- ↑ Landauer, T. K., Foltz, P. W., & Laham, D. (1998). Introduction to Latent Semantic Analysis. Discourse Processes, 25, 259-284
- ^ Susan T. Dumais (2005). "Latent Semantic Analysis". Annual Review of Information Science and Technology. 38: 188-230. doi:10.1002/aris.1440380105.
- ^ "US Patent 4,839,853". 2 Aralık 2017 tarihinde kaynağından arşivlendi. (now expired)
- ^ "The Latent Semantic Indexing home page". 3 Aralık 1998 tarihinde kaynağından arşivlendi.
- ^ "image". topicmodels.west.uni-koblenz.de. 17 Mart 2023 tarihinde kaynağından arşivlendi.
- ^ Markovsky I. (2012) Low-Rank Approximation: Algorithms, Implementation, Applications, Springer, 2012, []
- ^ Alain Lifchitz; Sandra Jhean-Larose; Guy Denhière (2009). "Effect of tuned parameters on an LSA multiple choice questions answering model" (PDF). Behavior Research Methods. 41 (4): 1201-1209. arXiv:0811.0146 $2. doi:10.3758/BRM.41.4.1201. (PMID) 19897829. 14 Mayıs 2012 tarihinde kaynağından arşivlendi (PDF). Erişim tarihi: free. Tarih değerini gözden geçirin:
|erişimtarihi=() - ^ a b Ramiro H. Gálvez; Agustín Gravano (2017). "Assessing the usefulness of online message board mining in automatic stock prediction systems". Journal of Computational Science. 19: 1877-7503. doi:10.1016/j.jocs.2017.01.001.
- ^ a b Altszyler, E.; Ribeiro, S.; Sigman, M.; Fernández Slezak, D. (2017). "The interpretation of dream meaning: Resolving ambiguity using Latent Semantic Analysis in a small corpus of text". Consciousness and Cognition. 56: 178-187. arXiv:1610.01520 $2. doi:10.1016/j.concog.2017.09.004. (PMID) 28943127.
- ^ Gerry J. Elman (October 2007). "Automated Patent Examination Support - A proposal". Biotechnology Law Report. 26 (5): 435-436. doi:10.1089/blr.2007.9896.
- ^ Marc W. Howard; Michael J. Kahana (1999). "Contextual Variability and Serial Position Effects in Free Recall" (PDF). APA PsycNet Direct.
- ^ Franklin M. Zaromb; ve diğerleri. (2006). Temporal Associations and Prior-List Intrusions in Free Recall (PDF). Interspeech'2005. 16 Mart 2023 tarihinde kaynağından arşivlendi (PDF). Erişim tarihi: 21 Nisan 2025.
- ^ Nelson, Douglas. "The University of South Florida Word Association, Rhyme and Word Fragment Norms". 1 Eylül 2011 tarihinde kaynağından arşivlendi. Erişim tarihi: 8 Mayıs 2011.
- ^ Geneviève Gorrell; Brandyn Webb (2005). "Generalized Hebbian Algorithm for Latent Semantic Analysis" (PDF). Interspeech'2005. 21 Aralık 2008 tarihinde kaynağından (PDF) arşivlendi.
- ^ a b Matthew Brand (2006). "Fast Low-Rank Modifications of the Thin Singular Value Decomposition". Linear Algebra and Its Applications. 415: 20-30. doi:10.1016/j.laa.2005.07.021. Erişim tarihi: free. Tarih değerini gözden geçirin:
|erişimtarihi=() - ^ "MATLAB". 28 Şubat 2014 tarihinde kaynağından arşivlendi.
- ^ "Python". 21 Nisan 2025 tarihinde kaynağından arşivlendi. Erişim tarihi: 21 Nisan 2025.
- ^ Ding, Yaguang; Zhu, Guofeng; Cui, Chenyang; Zhou, Jian; Tao, Liang (2011). "A parallel implementation of Singular Value Decomposition based on Map-Reduce and PARPACK". Proceedings of 2011 International Conference on Computer Science and Network Technology. ss. 739-741. doi:10.1109/ICCSNT.2011.6182070. ISBN .
- ^ a b Deerwester, Scott; Dumais, Susan T.; Furnas, George W.; Landauer, Thomas K.; Harshman, Richard (1990). "Indexing by latent semantic analysis". Journal of the American Society for Information Science. 41 (6): 391-407. doi:10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9.
- ^ Abedi, Vida; Yeasin, Mohammed; Zand, Ramin (27 Kasım 2014). "Empirical study using network of semantically related associations in bridging the knowledge gap". Journal of Translational Medicine. 12 (1): 324. doi:10.1186/s12967-014-0324-9. (PMC) 4252998 $2. (PMID) 25428570.
- ^ Salakhutdinov, Ruslan, and Geoffrey Hinton. "Semantic hashing." RBM 500.3 (2007): 500.
- ^ a b c Deerwester, S., et al, Improving Information Retrieval with Latent Semantic Indexing, Proceedings of the 51st Annual Meeting of the American Society for Information Science 25, 1988, pp. 36–40.
- ^ Benzécri, J.-P. (1973). L'Analyse des Données. Volume II. L'Analyse des Correspondences. Paris, France: Dunod.
- ^ Furnas, G. W.; Landauer, T. K.; Gomez, L. M.; Dumais, S. T. (1987). "The vocabulary problem in human-system communication". Communications of the ACM. 30 (11): 964-971. doi:10.1145/32206.32212.
- ^ Landauer, T., et al., Learning Human-like Knowledge by Singular Value Decomposition: A Progress Report 25 Ekim 2020 tarihinde Wayback Machine sitesinde arşivlendi., M. I. Jordan, M. J. Kearns & (Eds.), Advances in Neural Information Processing Systems 10, Cambridge: MIT Press, 1998, pp. 45–51.
- ^ Dumais, S.; Platt, J.; Heckerman, D.; Sahami, M. (1998). "Inductive learning algorithms and representations for text categorization" (PDF). Proceedings of the seventh international conference on Information and knowledge management - CIKM '98. ss. 148. doi:10.1145/288627.288651. ISBN .
- ^ Homayouni, R.; Heinrich, K.; Wei, L.; Berry, M. W. (2004). "Gene clustering by Latent Semantic Indexing of MEDLINE abstracts". Bioinformatics. 21 (1): 104-115. doi:10.1093/bioinformatics/bth464. (PMID) 15308538.
- ^ Price, R. J.; Zukas, A. E. (2005). "Application of Latent Semantic Indexing to Processing of Noisy Text". Intelligence and Security Informatics. Lecture Notes in Computer Science. 3495. s. 602. doi:10.1007/11427995_68. ISBN .
- ^ Ding, C., A Similarity-based Probability Model for Latent Semantic Indexing, Proceedings of the 22nd International ACM SIGIR Conference on Research and Development in Information Retrieval, 1999, pp. 59–65.
- ^ Bartell, B., Cottrell, G., and Belew, R., Latent Semantic Indexing is an Optimal Special Case of Multidimensional Scaling[], Proceedings, ACM SIGIR Conference on Research and Development in Information Retrieval, 1992, pp. 161–167.
- ^ Graesser, A.; Karnavat, A. (2000). "Latent Semantic Analysis Captures Causal, Goal-oriented, and Taxonomic Structures". Proceedings of CogSci 2000: 184-189.
- ^ Dumais, S.; Nielsen, J. (1992). "Automating the assignment of submitted manuscripts to reviewers". Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval - SIGIR '92. ss. 233-244. doi:10.1145/133160.133205. ISBN .
- ^ Berry, M. W., and Browne, M., Understanding Search Engines: Mathematical Modeling and Text Retrieval, Society for Industrial and Applied Mathematics, Philadelphia, (2005).
- ^ Landauer, T., et al., Handbook of Latent Semantic Analysis, Lawrence Erlbaum Associates, 2007.
- ^ Berry, Michael W., Dumais, Susan T., O'Brien, Gavin W., Using Linear Algebra for Intelligent Information Retrieval 26 Nisan 2025 tarihinde Wayback Machine sitesinde arşivlendi., December 1994, SIAM Review 37:4 (1995), pp. 573–595.
- ^ Dumais, S., Latent Semantic Analysis, ARIST Review of Information Science and Technology, vol. 38, 2004, Chapter 4.
- ^ Best Practices Commentary on the Use of Search and Information Retrieval Methods in E-Discovery, the Sedona Conference, 2007, pp. 189–223.
- ^ Foltz, P. W. and Dumais, S. T. Personalized Information Delivery: An analysis of information filtering methods, Communications of the ACM, 1992, 34(12), 51-60.
- ^ Gong, Y., and Liu, X., Creating Generic Text Summaries 15 Nisan 2024 tarihinde Wayback Machine sitesinde arşivlendi., Proceedings, Sixth International Conference on Document Analysis and Recognition, 2001, pp. 903–907.
- ^ Bradford, R., Efficient Discovery of New Information in Large Text Databases, Proceedings, IEEE International Conference on Intelligence and Security Informatics, Atlanta, Georgia, LNCS Vol. 3495, Springer, 2005, pp. 374–380.
- ^ Bradford, R. B. (2006). "Application of Latent Semantic Indexing in Generating Graphs of Terrorist Networks". Intelligence and Security Informatics. Lecture Notes in Computer Science. 3975. ss. 674-675. doi:10.1007/11760146_84. ISBN .
- ^ Yarowsky, D., and Florian, R., Taking the Load off the Conference Chairs: Towards a Digital Paper-routing Assistant 8 Ağustos 2019 tarihinde Wayback Machine sitesinde arşivlendi., Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in NLP and Very-Large Corpora, 1999, pp. 220–230.
- ^ Caron, J., Applying LSA to Online Customer Support: A Trial Study, Unpublished Master's Thesis, May 2000.
- ^ Soboroff, I., et al, Visualizing Document Authorship Using N-grams and Latent Semantic Indexing, Workshop on New Paradigms in Information Visualization and Manipulation, 1997, pp. 43–48.
- ^ Monay, F., and Gatica-Perez, D., On Image Auto-annotation with Latent Space Models 17 Ağustos 2017 tarihinde Wayback Machine sitesinde arşivlendi., Proceedings of the 11th ACM international conference on Multimedia, Berkeley, CA, 2003, pp. 275–278.
- ^ Maletic, J.; Marcus, A. (November 13–15, 2000). "Using latent semantic analysis to identify similarities in source code to support program understanding". Proceedings 12th IEEE Internationals Conference on Tools with Artificial Intelligence. ICTAI 2000. ss. 46-53. doi:10.1109/TAI.2000.889845. ISBN .
- ^ Gee, K., Using Latent Semantic Indexing to Filter Spam, in: Proceedings, 2003 ACM Symposium on Applied Computing, Melbourne, Florida, pp. 460–464.
- ^ Landauer, T., Laham, D., and Derr, M., From Paragraph to Graph: Latent Semantic Analysis for Information Visualization 21 Ocak 2022 tarihinde Wayback Machine sitesinde arşivlendi., Proceedings of the National Academy of Sciences, 101, 2004, pp. 5214–5219.
- ^ Foltz, Peter W., Laham, Darrell, and Landauer, Thomas K., Automated Essay Scoring: Applications to Educational Technology, Proceedings of EdMedia, 1999.
- ^ Gordon, M., and Dumais, S., Using Latent Semantic Indexing for Literature Based Discovery 10 Şubat 2023 tarihinde Wayback Machine sitesinde arşivlendi., Journal of the American Society for Information Science, 49(8), 1998, pp. 674–685.
- ^ There Has to be a Better Way to Search, 2008, White Paper, Fios, Inc.
- ^ Karypis, G., Han, E., Fast Supervised Dimensionality Reduction Algorithm with Applications to Document Categorization and Retrieval, Proceedings of CIKM-00, 9th ACM Conference on Information and Knowledge Management.
- ^ Radim Řehůřek (2011). "Subspace Tracking for Latent Semantic Analysis". Advances in Information Retrieval. Lecture Notes in Computer Science. 6611. ss. 289-300. doi:10.1007/978-3-642-20161-5_29. ISBN .
- ^ Bradford, R., An Empirical Study of Required Dimensionality for Large-scale Latent Semantic Indexing Applications 2 Ocak 2018 tarihinde Wayback Machine sitesinde arşivlendi., Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, California, USA, 2008, pp. 153–162.
- ^ Landauer, Thomas K., and Dumais, Susan T., Latent Semantic Analysis, Scholarpedia, 3(11):4356, 2008.
- ^ Landauer, T. K., Foltz, P. W., & Laham, D. (1998). Introduction to Latent Semantic Analysis. Discourse Processes, 25, 259-284
Daha fazla okuma
- Landauer, Thomas; Foltz, Peter W.; Laham, Darrell (1998). "Introduction to Latent Semantic Analysis" (PDF). Discourse Processes. 25 (2–3): 259-284. doi:10.1080/01638539809545028.
- Deerwester, Scott; Dumais, Susan T.; Furnas, George W.; Landauer, Thomas K.; Harshman, Richard (1990). "Indexing by Latent Semantic Analysis" (PDF). Journal of the American Society for Information Science. 41 (6): 391-407. doi:10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9. 17 Temmuz 2012 tarihinde kaynağından (PDF) arşivlendi. Original article where the model was first exposed.
- Berry, Michael; Dumais, Susan T.; O'Brien, Gavin W. (1995). "Using Linear Algebra for Intelligent Information Retrieval". 23 Şubat 2008 tarihinde kaynağından arşivlendi. (PDF) Archived 2018-11-23 at the Wayback Machine. Illustration of the application of LSA to document retrieval.
- Chicco, D; Masseroli, M (2015). "Software suite for gene and protein annotation prediction and similarity search". IEEE/ACM Transactions on Computational Biology and Bioinformatics. 12 (4): 837-843. doi:10.1109/TCBB.2014.2382127. (PMID) 26357324.
- "Latent Semantic Analysis". InfoVis. 18 Şubat 2020 tarihinde kaynağından arşivlendi. Erişim tarihi: 1 Temmuz 2005.
- Fridolin Wild (23 Kasım 2005). "An Open Source LSA Package for R". CRAN. 10 Eylül 2016 tarihinde kaynağından arşivlendi. Erişim tarihi: 20 Kasım 2006.
- , . "A Solution to Plato's Problem: The Latent Semantic Analysis Theory of Acquisition, Induction, and Representation of Knowledge". 26 Ocak 2025 tarihinde kaynağından arşivlendi. Erişim tarihi: 2 Temmuz 2007.
Dış bağlantılar
LSA ile ilgili makaleler
Latent Semantic Analysis, LSA'nın yaratıcılarından Tom Landauer'in LSA hakkında yazdığı bir scholarpedia makalesidir.
Konuşmalar ve gösteriler
- LSA Genel Bakış, Prof. Thomas Hofmann'ın konuşması Archived LSA'yı, Bilgi Alma'daki uygulamalarını ve bağlantılarını açıklayan.
- Windows için C# dilinde tam LSA örnek kodu . Demo kodu, metin dosyalarının numaralandırılması, durdurma sözcüklerinin filtrelenmesi, köklendirme, belge-terim matrisi oluşturulması ve SVD'yi içermektedir.
Uygulamalar
Bilgi Alma, Doğal Dil İşleme (NLP), Bilişsel Bilimler ve Hesaplamalı Dilbilim alanlarındaki alanlar arası uygulamaları nedeniyle LSA, pek çok farklı türde uygulamayı desteklemek için uygulanmıştır.
- Sense Clusters, LSA'nın Bilgi Alma odaklı bir Perl uygulamasıdır
- S-Space Paketi, LSA'nın Hesaplamalı Dilbilim ve Bilişsel Bilim odaklı Java uygulamasıdır
- Semantic Vectors, Lucene terim-belge matrislerine Rastgele Projeksiyon, LSA ve Yansıtıcı Rastgele İndeksleme uygular
- Infomap Projesi, LSA'nın NLP odaklı bir C uygulamasıdır (semanticvectors projesi tarafından değiştirilmiştir)
- Metinden Matris Oluşturucu adresinde Archived, LSA desteğiyle metin koleksiyonlarından terim-belge matrisleri oluşturmak için bir MATLAB Araç Kutusu
- , RAM'den büyük matrisler için LSA'nın Python uygulamasını içerir.
wikipedia, wiki, viki, vikipedia, oku, kitap, kütüphane, kütübhane, ara, ara bul, bul, herşey, ne arasanız burada,hikayeler, makale, kitaplar, öğren, wiki, bilgi, tarih, yukle, izle, telefon için, turk, türk, türkçe, turkce, nasıl yapılır, ne demek, nasıl, yapmak, yapılır, indir, ücretsiz, ücretsiz indir, bedava, bedava indir, mp3, video, mp4, 3gp, jpg, jpeg, gif, png, resim, müzik, şarkı, film, film, oyun, oyunlar, mobil, cep telefonu, telefon, android, ios, apple, samsung, iphone, xiomi, xiaomi, redmi, honor, oppo, nokia, sonya, mi, pc, web, computer, bilgisayar
Bu maddede bircok sorun bulunmaktadir Lutfen sayfayi gelistirin veya bu sorunlar konusunda bir yorum yapin Bu madde Vikipedi bicem el kitabina uygun degildir Maddeyi Vikipedi standartlarina uygun bicimde duzenleyerek Vikipedi ye katkida bulunabilirsiniz Gerekli duzenleme yapilmadan bu sablon kaldirilmamalidir Nisan 2025 Bu madde onerilmeyen bicimde kaynaklandirilmistir Gosterilen kaynaklar kaynak gosterme sablonlari kullanilarak dipnot belirtme bicemine uygun olarak duzenlenmelidir Nisan 2025 Bu sablonun nasil ve ne zaman kaldirilmasi gerektigini ogrenin Bu madde oksuz maddedir zira herhangi bir maddeden bu maddeye verilmis bir baglanti yoktur Lutfen ilgili maddelerden bu sayfaya baglanti vermeye calisin Nisan 2025 Gizli anlamsal analiz LSA dogal dil islemede ozellikle bir dizi belge ve icerdikleri terimler arasindaki iliskileri belgeler ve terimlerle ilgili bir dizi kavram ureterek analiz eden bir tekniktir LSA anlamca yakin olan kelimelerin benzer metin parcalarinda bulunacagini varsayar Buyuk bir metin parcasindan belge basina kelime sayilarini iceren bir matris satirlar benzersiz kelimeleri sutunlar ise her bir belgeyi temsil eder olusturulur ve sutunlar arasindaki benzerlik yapisini korurken satir sayisini azaltmak icin SVD adi verilen bir matematiksel teknik kullanilir Daha sonra belgeler herhangi iki sutun arasindaki gore karsilastirilir 1 e yakin degerler cok benzer belgeleri temsil ederken 0 a yakin degerler cok farkli belgeleri temsil eder Gizli anlamsal yapiyi kullanan bir bilgi alma teknigi 1988 de ve tarafindan patentlendi Bilgi almaya uygulanmasi baglaminda bazen gizli anlamsal indeksleme LSI olarak adlandirilir Genel bakis source source source source source Belge kelime matrisinde konu algilama surecinin animasyonu Her sutun bir belgeye her satir bir kelimeye karsilik geliyor Bir hucre bir belgedeki bir kelimenin agirligini depolar ornegin tf idf ile koyu hucreler yuksek agirliklari gosterir LSA benzer sozcukleri iceren belgelerin yani sira benzer bir belge kumesinde gecen sozcukleri de gruplandirir Ortaya cikan desenler gizli bilesenleri tespit etmek icin kullanilir Olusum matrisi LSA belgelerdeki terimlerin olusumlarini tanimlayan bir belge terim matrisi kullanabilir bu satirlari terimlere ve sutunlari belgelere karsilik gelen Matrisin ogelerinin agirliklandirilmasinin tipik bir ornegi tf idf dir terim sikligi ters belge sikligi Matrisin bir ogesinin agirligi terimlerin her bir belgede gorundugu sayiyla orantilidir nadir terimler goreceli onemlerini yansitacak sekilde agirliklandirilir Bu matris standart semantik modellerde de yaygindir ancak matrislerin matematiksel ozellikleri her zaman kullanilmadigindan mutlaka acikca bir matris olarak ifade edilmesi gerekmez Rutbe dusurme Olusum matrisinin olusturulmasindan sonra LSA terim belge matrisine bulur Bu yaklasimlarin cesitli nedenleri olabilir Orijinal terim belge matrisinin hesaplama kaynaklari icin cok buyuk oldugu varsayilir bu durumda yaklasik dusuk rutbeli matris bir yaklasim bir en az ve gerekli kotuluk olarak yorumlanir Orijinal terim belge matrisinin gurultulu oldugu varsayilir ornegin terimlerin anekdot niteligindeki ornekleri elenecektir Bu bakis acisindan bakildiginda yaklasik matris gurultusuzlestirilmis bir matris orijinalinden daha iyi bir matris olarak yorumlanir Orijinal terim belge matrisinin gercek terim belge matrisine kiyasla asiri varsayilmaktadir Yani orijinal matris yalnizca her belgede gercekten bulunan kelimeleri listeler oysa biz her belgeyle iliskili tum kelimelerle ilgileniyor olabiliriz bu genellikle esanlamlilik nedeniyle cok daha buyuk bir kumedir araba kamyon cicek 1 3452 araba 0 2828 kamyon cicek Bu es anlamliligi belirleme sorununu hafifletir cunku siralamanin dusurulmesinin benzer anlamlara sahip terimlerle iliskili boyutlari birlestirmesi beklenir Ayni zamanda cok anlamli sozcuklerin dogru yone isaret eden bilesenleri benzer bir anlami paylasan sozcuklerin bilesenlerine eklendiginden sorununu da kismen hafifletir Buna karsilik diger yonlere isaret eden bilesenler ya basitce birbirlerini iptal etme egilimindedir ya da en kotusu amaclanan yone karsilik gelen yonlerdeki bilesenlerden daha kucuk olma egilimindedir Turetme Izin vermek X displaystyle X elemanin bulundugu bir matris olsun i j displaystyle i j terimin olusumunu aciklar i displaystyle i belgede j displaystyle j ornegin bu frekans olabilir X displaystyle X soyle gorunecek dj tiT x1 1 x1 j x1 n xi 1 xi j xi n xm 1 xm j xm n displaystyle begin matrix amp textbf d j amp downarrow textbf t i T rightarrow amp begin bmatrix x 1 1 amp dots amp x 1 j amp dots amp x 1 n vdots amp ddots amp vdots amp ddots amp vdots x i 1 amp dots amp x i j amp dots amp x i n vdots amp ddots amp vdots amp ddots amp vdots x m 1 amp dots amp x m j amp dots amp x m n end bmatrix end matrix Simdi bu matristeki bir satir her bir belgeye iliskin iliskisini veren bir terime karsilik gelen bir vektor olacaktir tiT xi 1 xi j xi n displaystyle textbf t i T begin bmatrix x i 1 amp dots amp x i j amp dots amp x i n end bmatrix Benzer sekilde bu matristeki bir sutun her terime olan iliskisini veren bir belgeye karsilik gelen bir vektor olacaktir dj x1 j xi j xm j displaystyle textbf d j begin bmatrix x 1 j vdots x i j vdots x m j end bmatrix Simdi nokta carpimi tiTtp displaystyle textbf t i T textbf t p Iki terim vektoru arasindaki korelasyon belgeler kumesi uzerindeki terimler arasindaki korelasyonu verir Matris urunu XXT displaystyle XX T tum bu nokta urunlerini icerir Oge i p displaystyle i p elemana esit olan p i displaystyle p i nokta carpimini icerir tiTtp displaystyle textbf t i T textbf t p tpTti displaystyle textbf t p T textbf t i Benzer sekilde matris XTX displaystyle X T X tum belge vektorleri arasindaki nokta urunlerini icerir ve terimler uzerindeki korelasyonlarini verir djTdq dqTdj displaystyle textbf d j T textbf d q textbf d q T textbf d j Simdi dogrusal cebir teorisinden bir ayristirma vardir X displaystyle X oyle ki U displaystyle U Ve V displaystyle V ve S displaystyle Sigma diyagonal bir matristir Buna SVD denir X USVT displaystyle begin matrix X U Sigma V T end matrix Bize terim ve belge korelasyonlarini veren matris urunleri daha sonra su hale gelir XXT USVT USVT T USVT VTTSTUT USVTVSTUT USSTUTXTX USVT T USVT VTTSTUT USVT VSTUTUSVT VSTSVT displaystyle begin matrix XX T amp amp U Sigma V T U Sigma V T T U Sigma V T V T T Sigma T U T U Sigma V T V Sigma T U T U Sigma Sigma T U T X T X amp amp U Sigma V T T U Sigma V T V T T Sigma T U T U Sigma V T V Sigma T U T U Sigma V T V Sigma T Sigma V T end matrix O zamandan beri SST displaystyle Sigma Sigma T Ve STS displaystyle Sigma T Sigma kosegen oldugunu goruyoruz U displaystyle U ozvektorleri icermelidir XXT displaystyle XX T sirasinda V displaystyle V ozvektorleri olmali XTX displaystyle X T X Her iki urunun de sifir olmayan girisleri tarafindan verilen ayni sifir olmayan oz degerleri vardir SST displaystyle Sigma Sigma T veya esit olarak sifir olmayan girdilerle STS displaystyle Sigma T Sigma Simdi ayristirma su sekilde gorunuyor XUSVT dj d j tiT x1 1 x1 j x1 n xi 1 xi j xi n xm 1 xm j xm n t iT u1 ul s1 0 0 sl v1 vl displaystyle begin matrix amp X amp amp amp U amp amp Sigma amp amp V T amp textbf d j amp amp amp amp amp amp amp hat textbf d j amp downarrow amp amp amp amp amp amp amp downarrow textbf t i T rightarrow amp begin bmatrix x 1 1 amp dots amp x 1 j amp dots amp x 1 n vdots amp ddots amp vdots amp ddots amp vdots x i 1 amp dots amp x i j amp dots amp x i n vdots amp ddots amp vdots amp ddots amp vdots x m 1 amp dots amp x m j amp dots amp x m n end bmatrix amp amp hat textbf t i T rightarrow amp begin bmatrix begin bmatrix textbf u 1 end bmatrix dots begin bmatrix textbf u l end bmatrix end bmatrix amp cdot amp begin bmatrix sigma 1 amp dots amp 0 vdots amp ddots amp vdots 0 amp dots amp sigma l end bmatrix amp cdot amp begin bmatrix begin bmatrix amp amp textbf v 1 amp amp end bmatrix vdots begin bmatrix amp amp textbf v l amp amp end bmatrix end bmatrix end matrix Degerler s1 sl displaystyle sigma 1 dots sigma l tekil degerler olarak adlandirilir ve u1 ul displaystyle u 1 dots u l Ve v1 vl displaystyle v 1 dots v l sol ve sag tekil vektorler Tek bir parcaya dikkat edin U displaystyle U katkida bulunan ti displaystyle textbf t i odur i th displaystyle i textrm th sira Bu satir vektorunun adinin su olmasina izin verin t iT displaystyle hat textrm t i T Benzer sekilde tek kismi VT displaystyle V T katkida bulunan dj displaystyle textbf d j odur j th displaystyle j textrm th kolon d j displaystyle hat textrm d j Bunlar ozvektorler degildir fakat tum ozvektorlere baglidirlar Sectiginizde ortaya cikiyor ki k displaystyle k en buyuk tekil degerler ve bunlara karsilik gelen tekil vektorler U displaystyle U Ve V displaystyle V rutbeyi alirsin k displaystyle k yaklasiklik X displaystyle X en kucuk hata ile Bu yaklasimin cok az bir hatasi vardir Ama daha da onemlisi artik terim ve belge vektorlerini bir anlamsal uzay olarak ele alabiliriz Satir terim vektoru t iT displaystyle hat textbf t i T sonra sahip oldu k displaystyle k onu daha dusuk boyutlu bir uzaya esleyen girdiler Bu yeni boyutlarin anlasilir hicbir kavrama iliskinligi yoktur Bunlar yuksek boyutlu uzayin dusuk boyutlu bir yaklasimidir Benzer sekilde belge vektoru d j displaystyle hat textbf d j bu dusuk boyutlu uzayda bir yaklasimdir Bu yaklasimi su sekilde yaziyoruz Xk UkSkVkT displaystyle X k U k Sigma k V k T Artik sunlari yapabilirsiniz Ilgili belgelerin nasil oldugunu gorun j displaystyle j Ve q displaystyle q vektorleri karsilastirarak dusuk boyutlu uzaydadir Sk d j displaystyle Sigma k cdot hat textbf d j Ve Sk d q displaystyle Sigma k cdot hat textbf d q genellikle ile Terimleri karsilastirma i displaystyle i Ve p displaystyle p vektorleri karsilastirarak Sk t i displaystyle Sigma k cdot hat textbf t i Ve Sk t p displaystyle Sigma k cdot hat textbf t p Dikkat t displaystyle hat textbf t artik bir sutun vektorudur Belgeler ve terim vektor gosterimleri kosinus gibi benzerlik olcutlerini kullanarak k ortalamalar gibi geleneksel kumeleme algoritmalari kullanilarak kumelenebilir Bir sorgu verildiginde bunu mini bir belge olarak goruntuleyin ve dusuk boyutlu uzaydaki belgelerinizle karsilastirin Ikincisini yapmak icin oncelikle sorgunuzu dusuk boyutlu uzaya cevirmeniz gerekir Bu durumda belgelerinizde kullandiginiz donusumun aynisini kullanmaniz gerektigi sezgiseldir d j Sk 1UkTdj displaystyle hat textbf d j Sigma k 1 U k T textbf d j Burada diyagonal matrisin tersinin oldugunu unutmayin Sk displaystyle Sigma k matris icindeki sifirdan farkli her degerin ters cevrilmesiyle bulunabilir Bu bir sorgu vektorunuz varsa su anlama gelir q displaystyle q ceviriyi sen yapmalisin q Sk 1UkTq displaystyle hat textbf q Sigma k 1 U k T textbf q Dusuk boyutlu uzaydaki belge vektorleriyle karsilastirmadan once Aynisini sozde terim vektorleri icin de yapabilirsiniz tiT t iTSkVkT displaystyle textbf t i T hat textbf t i T Sigma k V k T t t iT tiTVk TSk 1 tiTVkSk 1 displaystyle hat textbf t i T textbf t i T V k T Sigma k 1 textbf t i T V k Sigma k 1 t i Sk 1VkTti displaystyle hat textbf t i Sigma k 1 V k T textbf t i Uygulamalar Yeni dusuk boyutlu uzay genellikle su amaclar icin kullanilabilir Dusuk boyutlu uzaydaki belgeleri karsilastirin veri kumelemesi belge siniflandirmasi Cevrilmis belgelerin temel kumesini analiz ettikten sonra diller arasinda benzer belgeleri bulun diller arasi bilgi alma Terimler arasindaki iliskileri bulun es anlamlilik ve Verilen bir terim sorgusunu dusuk boyutlu uzaya cevir ve eslesen belgeleri bul bilgi alma Ornegin coktan secmeli sorularda MCQ cevaplama modelinde oldugu gibi kucuk terim gruplari arasinda anlamsal bir sekilde yani bir bilgi govdesi baglaminda en iyi benzerligi bulun Makine ogrenimi metin madenciligi sistemlerinin ozellik alanini genisletin Metin govdesindeki kelime iliskisini analiz edin Es anlamlilik ve cok anlamlilik dogal dil islemedeki temel problemlerdir Es anlamlilik ayni dusunceyi farkli sozcuklerle anlatmaktir Bu nedenle arama motorunda yapilan bir sorgu sorguda gorunen kelimeleri icermeyen ilgili bir belgeye ulasmayi basaramayabilir Ornegin doktorlar icin yapilan bir arama kelimeler ayni anlama gelse bile hekimler kelimesini iceren bir belge dondurmeyebilir Cok anlamlilik ayni kelimenin birden fazla anlama gelmesi durumudur Bu nedenle arama sonucunda aranan kelimelerin yanlis anlamlarini iceren alakasiz belgelere ulasilabilmektedir Ornegin agac kelimesini arayan bir botanikci ile bir bilgisayar bilimci muhtemelen farkli belge kumeleri isteyecektir Ticari uygulamalar LSA patentler icin arastirmalarinin yapilmasina yardimci olmak icin kullanilmistir Insan hafizasindaki uygulamalar Gizli Anlamsal Analizin insan belleginin incelenmesinde ozellikle serbest hatirlama ve bellek arama alanlarinda kullanimi yayginlasmistir Iki kelimenin semantik benzerligi LSA ile olculdugu gibi ile kelimelerin rastgele ortak isimlerden olusan calisma listelerinin kullanildigi serbest hatirlama gorevlerinde birbiri ardina hatirlanma olasiligi arasinda pozitif bir korelasyon vardir Ayrica bu durumlarda benzer kelimeler arasindaki yanitlar arasi surenin farkli kelimeler arasindaki yanitlara gore cok daha hizli oldugunu da kaydettiler Bu bulgulara adi verilir Katilimcilar calisilan ogeleri hatirlarken hata yaptiklarinda bu hatalarin daha cok istenen ogeyle anlamsal olarak daha iliskili olan ve daha once calisilmis bir listede bulunan ogeler olma egilimi gosterdigi goruldu Bu tur onceki liste ihlalleri artik cagrildiklari gibi geri cagirma icin gecerli listedeki ogelerle rekabet ediyor gibi gorunuyor WAS adi verilen baska bir model de bir dizi deneyden serbest iliskilendirme verileri toplayarak hafiza calismalarinda kullanilir ve 72 000 den fazla farkli kelime cifti icin kelime iliskisi olcumlerini icerir Uygulama genellikle buyuk matris yontemleri ornegin kullanilarak hesaplanir ancak buyuk tam rutbeli matrisin bellekte tutulmasini gerektirmeyen bir sinir agi benzeri yaklasim yoluyla artimli olarak ve buyuk olcude azaltilmis kaynaklarla da hesaplanabilir Hizli artimli dusuk bellekli buyuk matrisli bir SVD algoritmasi gelistirildi Bu hizli algoritmalarin MATLAB ve Python uygulamalari mevcuttur Gorrell ve Webb in 2005 stokastik yaklasiminin aksine Brand in algoritmasi 2003 kesin bir cozum sunmaktadir Son yillarda SVD nin hesaplama karmasikligini azaltmak icin ilerleme kaydedildi ornegin paralel ozdeger ayristirmasi gerceklestirmek icin paralel bir ARPACK algoritmasi kullanilarak karsilastirilabilir tahmin kalitesi saglanirken SVD hesaplama maliyetinin hizlandirilmasi mumkun oldu Sinirlamalar LSA nin bazi dezavantajlari sunlardir Ortaya cikan boyutlarin yorumlanmasi zor olabilir Ornegin araba kamyon cicek 1 3452 araba 0 2828 kamyon cicek dd 1 3452 otomobil 0 2828 kamyon bileseni arac olarak yorumlanabilir Ancak vakalarin yakin olmasi cok olasidir araba sise cicek 1 3452 araba 0 2828 sise cicek dd gerceklesecektir Bu matematiksel duzeyde gerekcelendirilebilen ancak dogal dilde hemen belirgin bir anlami olmayan sonuclara yol acar Yine de 1 3452 araba 0 2828 sise bileseni hakli gorulebilir cunku hem siseler hem de arabalar seffaf ve opak parcalara sahiptir insan yapimidir ve yuksek olasilikla yuzeylerinde logolar kelimeler bulunur dolayisiyla bircok yonden bu iki kavram anlamsal olarak aynidir Yani soz konusu bir dil icinde atanacak kolayca bulunabilen bir kelime olmayabilir ve aciklanabilirlik basit kelime sinif kavram atama gorevi yerine bir analiz gorevi haline gelir LSA yani bir kelimenin birden fazla anlamini yalnizca kismen yakalayabilir cunku bir kelimenin her bir kullanimi kelime uzayda tek bir nokta olarak temsil edildigi icin ayni anlama sahipmis gibi ele alinir Ornegin Yonetim Kurulu Baskani ifadesini iceren bir belgede baskan kelimesinin gecmesi ile baskan yapimcisi ifadesini iceren ayri bir belgede baskan kelimesinin gecmesi ayni kabul edilir Bu davranis vektor gosteriminin govdedeki tum kelimelerin farkli anlamlarinin ortalamasi olmasiyla sonuclaniyor ve bu da karsilastirmayi zorlastirabiliyor Ancak sozcuklerin bir metin boyunca sahip olmasi yani tum anlamlarin esit derecede olasi olmamasi nedeniyle etki genellikle azalir Bir metnin siralanmamis bir kelime koleksiyonu olarak gosterildigi kelime torbasi modelinin BOW sinirlamalari Kelime torbasi modeli BOW sinirlamalarindan bazilarini ele almak icin terimler arasinda dogrudan ve dolayli iliskilerin yani sira bulmak icin coklu gram sozlugu kullanilabilir LSA nin olasiliksal modeli gozlemlenen verilerle uyusmuyor LSA kelimelerin ve belgelerin ortak bir Gauss modeli olusturdugunu varsayar ergodik hipotez oysa bir Poisson dagilimi gozlemlenmistir Bu nedenle standart LSA dan daha iyi sonuclar verdigi bildirilen cok terimli bir modele dayanan daha yeni bir alternatiftir Alternatif yontemler Anlamsal karma Anlamsal karma isleminde belgeler anlamsal olarak benzer belgelerin yakin adreslerde yer almasi icin bir sinir agi araciligiyla bellek adreslerine eslenir Derin sinir agi esas olarak buyuk bir belge kumesinden elde edilen kelime sayisi vektorlerinin olusturur Sorgu belgesine benzeyen belgeler sorgu belgesinin adresinden yalnizca birkac bit farkli olan tum adreslere erisilerek bulunabilir Karma kodlamanin verimliligini yaklasik eslesmeye genisletmenin bu yolu su anda en hizli yontem olan cok daha hizlidir aciklama gerekli Gizli anlamsal dizinleme Gizli anlamsal dizinleme LSI yapilandirilmamis bir metin koleksiyonunda yer alan terimler ve kavramlar arasindaki iliskilerdeki kaliplari belirlemek icin SVD adi verilen bir matematiksel teknik kullanan bir dizinleme ve alma yontemidir LSI ayni baglamlarda kullanilan sozcuklerin benzer anlamlara sahip olma egiliminde oldugu ilkesine dayanir LSI nin temel bir ozelligi benzer baglamlarda gecen terimler arasinda iliskiler kurarak bir kavramsal icerigini cikarma yetenegidir LSI ayni zamanda tarafindan 1970 lerin basinda gelistirilen cok degiskenli bir istatistiksel teknik olan belgelerdeki kelime sayimlarindan olusturulan bir uygulanmasidir Bir metin koleksiyonunda latent olan semantically iliskili terimleri iliskilendirme yetenegi nedeniyle latent semantic indeksleme olarak adlandirilan bu yontem ilk olarak 1980 lerin sonlarinda metinlere uygulandi Gizli anlam analizi LSA olarak da adlandirilan bu yontem bir metindeki kelimelerin kullaniminda altta yatan gizli anlamsal yapiyi ortaya cikarir ve bunun kullanici sorgularina yanit olarak metnin anlamini cikarmak icin nasil kullanilabilecegini yaygin olarak kavram aramalari olarak adlandirilir LSI dan gecmis bir belge kumesine yonelik sorgular veya kavram aramalari arama olcutleriyle belirli bir kelime veya kelimeleri paylasmasa bile arama olcutleriyle anlam bakimindan kavramsal olarak benzer sonuclar dondurecektir LSI nin faydalari LSI ve vektor uzayi modellerinin en sorunlu kisitlamalarindan biri olan geri cagirmayi artirarak esanlamliligin ustesinden gelmeye yardimci olur Es anlamlilik cogu zaman belge yazarlari ile bilgi arama sistemlerinin kullanicilari tarafindan kullanilan kelime dagarcigindaki uyumsuzluklarin nedenidir Sonuc olarak Boole veya anahtar sozcuk sorgulari genellikle alakasiz sonuclar dondurur ve alakali bilgileri kacirir LSI ayni zamanda otomatik belge kategorizasyonu gerceklestirmek icin de kullanilir Aslinda bircok deney LSI ile insanlarin metni isleme ve kategorize etme bicimleri arasinda bir dizi korelasyon oldugunu gostermistir Belge kategorizasyonu belgelerin kategorilerin kavramsal icerigine benzerliklerine gore bir veya daha fazla onceden tanimlanmis kategoriye atanmasidir LSI her kategori icin kavramsal temeli olusturmak amaciyla ornek belgeler kullanir Kategorizasyon islemi sirasinda kategorilendirilen dokumanlarda yer alan kavramlar ornek ogelerde yer alan kavramlarla karsilastirilir ve icerdikleri kavramlar ile ornek dokumanlarda yer alan kavramlar arasindaki benzerliklere gore dokumanlara bir veya birden fazla kategori atanir LSI kullanilarak belgelerin kavramsal icerigine dayali dinamik kumeleme de gerceklestirilebilir Kumeleme her kumenin kavramsal temelini olusturmak icin ornek belgeler kullanilmadan belgeleri kavramsal benzerliklerine gore gruplandirmanin bir yoludur Bu yapilandirilmamis metinlerden olusan bilinmeyen bir koleksiyonla ugrasirken cok faydalidir LSI tamamen matematiksel bir yaklasim kullandigi icin dilden bagimsizdir Bu LSI in sozluk ve es anlamlilar sozlugu gibi yardimci yapilarin kullanimina ihtiyac duymadan herhangi bir dilde yazilmis bilginin anlamsal icerigini ortaya cikarmasini saglar LSI ayni zamanda diller arasi ve ornek tabanli kategorizasyon da gerceklestirebilir Ornegin sorgular tek bir dilde ornegin Ingilizce de yapilabilir ve tamamen farkli bir dilden veya birden fazla dilden olussa bile kavramsal olarak benzer sonuclar dondurulur kaynak belirtilmeli LSI yalnizca kelimelerle calismakla sinirli degildir Ayrica keyfi karakter dizilerini de isleyebilir Metin olarak ifade edilebilen herhangi bir nesne LSI vektor uzayinda temsil edilebilir Ornegin MEDLINE ozetleriyle yapilan testler LSI nin MEDLINE atiflarinin basliklarinda ve ozetlerinde yer alan biyolojik bilgilerin kavramsal modellemesine dayali olarak genleri etkili bir sekilde siniflandirabildigini gostermistir LSI yeni ve degisen terminolojiye otomatik olarak uyum saglar ve gurultuye yani yanlis yazilmis kelimeler tipografik hatalar okunamayan karakterler vb karsi cok toleransli oldugu gosterilmistir Bu ozellikle Optik Karakter Tanima OCR ve konusmadan metne donusturme yoluyla turetilen metinleri kullanan uygulamalar icin onemlidir LSI ayni zamanda seyrek belirsiz ve celiskili verilerle de etkili bir sekilde basa cikar LSI nin etkili olabilmesi icin metnin cumle biciminde olmasi gerekmez Listeler serbest bicimli notlar e posta web tabanli icerik vb ile calisabilir Bir metin koleksiyonu birden fazla terim icerdigi surece LSI metinde yer alan onemli terimler ve kavramlar arasindaki iliskilerdeki kaliplari belirlemek icin kullanilabilir LSI bir dizi kavramsal eslestirme sorununa yararli bir cozum oldugunu kanitladi Bu teknigin nedensel hedef odakli ve taksonomik bilgiler de dahil olmak uzere temel iliski bilgilerini yakaladigi gosterilmistir LSI zaman cizelgesi 1960 larin ortasi Faktor analizi teknigi ilk kez tanimlandi ve test edildi H Borko ve M Bernick 1988 LSI teknigi hakkinda oncu makale yayinlandi 1989 Orijinal patent verildi 1992 Makaleleri gozden gecirenlere atamak icin LSI nin ilk kullanimi 1994 LSI nin diller arasi uygulanmasi icin patent verildi Landauer ve ark 1995 LSI nin denemeleri notlandirmak icin ilk kullanimi Foltz ve digerleri Landauer ve digerleri 1999 Yapilandirilmamis metinlerin analizi icin istihbarat topluluguna yonelik LSI teknolojisinin ilk uygulamasi 2002 Istihbarat tabanli devlet kurumlarina SAIC LSI tabanli urun teklifi LSI nin Matematigi LSI bir metin koleksiyonundaki kavramsal iliskileri ogrenmek icin yaygin dogrusal cebir tekniklerini kullanir Genel olarak surec agirlikli bir terim belge matrisi olusturmayi matris uzerinde yapmayi ve matrisi kullanarak metinde yer alan kavramlari belirlemeyi icerir LSI bir terim belge matrisi olusturarak baslar A displaystyle A olaylarin meydana gelisini tespit etmek icin m displaystyle m bir koleksiyon icindeki benzersiz terimler n displaystyle n belgeler Bir terim belge matrisinde her terim bir satirla ve her belge bir sutunla temsil edilir her matris hucresi aij displaystyle a ij baslangicta iliskili terimin belirtilen belgede gorundugu zaman sayisini temsil eder tfij displaystyle mathrm tf ij Bu matris genellikle cok buyuk ve cok seyrektir Bir terim belge matrisi olusturulduktan sonra verileri kosullandirmak icin ona yerel ve kuresel agirliklandirma fonksiyonlari uygulanabilir Agirliklandirma fonksiyonlari her hucreyi donusturur aij displaystyle a ij ile ilgili A displaystyle A yerel bir terim agirliginin urunu olmak uzere lij displaystyle l ij bir terimin bir belgedeki goreceli sikligini ve genel bir agirligi tanimlayan gi displaystyle g i Bu terim tum belge koleksiyonunda terimin goreceli sikligini aciklar Bazi yaygin yerel agirliklandirma fonksiyonlari asagidaki tabloda tanimlanmistir Ikili lij 1 displaystyle l ij 1 eger terim belgede mevcutsa yoksa 0 displaystyle 0 TerimFrekans lij tfij displaystyle l ij mathrm tf ij terimin ortaya cikis sayisi i displaystyle i belgede j displaystyle j Kayit lij log tfij 1 displaystyle l ij log mathrm tf ij 1 Augnorm lij tfijmaxi tfij 12 displaystyle l ij frac Big frac mathrm tf ij max i mathrm tf ij Big 1 2 Asagidaki tabloda bazi yaygin kuresel agirliklandirma fonksiyonlari tanimlanmistir Ikili gi 1 displaystyle g i 1 Normal gi 1 jtfij2 displaystyle g i frac 1 sqrt sum j mathrm tf ij 2 GfIdf gi gfi dfi displaystyle g i mathrm gf i mathrm df i Neresi gfi displaystyle mathrm gf i terimin toplam sayisidir i displaystyle i tum koleksiyonda bulunur ve dfi displaystyle mathrm df i terimdeki belge sayisidir i displaystyle i meydana gelmek gi log2 n1 dfi displaystyle g i log 2 frac n 1 mathrm df i Entropi gi 1 jpijlog pijlog n displaystyle g i 1 sum j frac p ij log p ij log n Neresi pij tfijgfi displaystyle p ij frac mathrm tf ij mathrm gf i LSI ile yapilan deneysel calismalar Log ve Entropi agirliklandirma fonksiyonlarinin pratikte bircok veri kumesiyle iyi calistigini bildirmektedir Baska bir deyisle her giris aij displaystyle a ij ile ilgili A displaystyle A su sekilde hesaplanir gi 1 jpijlog pijlog n displaystyle g i 1 sum j frac p ij log p ij log n aij gi log tfij 1 displaystyle a ij g i log mathrm tf ij 1 Siralama dusurulmus tekil deger ayristirmasi Metinde yer alan terimler ve kavramlar arasindaki iliskilerdeki oruntuleri belirlemek icin matris uzerinde rutbesi dusurulmus yapilir SVD LSI nin temelini olusturur Tek terim frekans matrisini yaklastirarak terim ve belge vektor uzaylarini hesaplar A displaystyle A uc baska matrise bir m by r terim kavram vektor matrisi T displaystyle T r ye r tekil degerler matrisi S displaystyle S ve n by r kavram belge vektor matrisi D displaystyle D Asagidaki iliskileri saglayan A TSDT displaystyle A approx TSD T TTT IrDTD Ir displaystyle T T T I r quad D T D I r S1 1 S2 2 Sr r gt 0Si j 0wherei j displaystyle S 1 1 geq S 2 2 geq ldots geq S r r gt 0 quad S i j 0 text where i neq j Formulde A bir metin koleksiyonundaki terim frekanslarinin m x n agirlikli matrisidir burada m benzersiz terim sayisi ve n belge sayisidir T r nin A nin rutbesi oldugu ve benzersiz boyutlarinin bir olcusu olan terim vektorlerinin m x r matrisinin hesaplanmasidir S azalan tekil degerlerden olusan r x r boyutlu bir kosegen matrisidir ve D belge vektorlerinden olusan n x r boyutlu bir matristir Daha sonra SVD yalnizca en buyuk k tutularak siralamayi azaltmak icin k tipik olarak 100 ila 300 boyutlarinda olan tekil deger matrisi S deki r kosegen girisi Bu terim ve belge vektor matrisi boyutlarini sirasiyla m x k ve n x k ye etkili bir sekilde azaltir SVD islemi bu indirgemeyle birlikte A nin orijinal uzayindaki gurultuyu ve diger istenmeyen eserleri azaltirken metindeki en onemli anlamsal bilgiyi koruma etkisine sahiptir Bu indirgenmis matris kumesi genellikle su sekilde degistirilmis bir formulle gosterilir A A k T k S k D kT dd dd dd dd dd dd Verimli LSI algoritmalari tam bir SVD hesaplayip sonra onu kesmek yerine sadece ilk k tekil degeri ve terim ve belge vektorlerini hesaplar Bu rutbe indirgemesinin esasen A matrisi uzerinde Temel Bilesen Analizi PCA yapmakla ayni oldugunu ancak PCA nin ortalamalari cikardigini unutmayin PCA A matrisinin seyrekligini kaybeder bu da onu buyuk sozlukler icin uygulanamaz hale getirebilir LSI vektor uzaylarini sorgulama ve genisletme Hesaplanan T k ve D k matrisleri belge koleksiyonundan turetilen kavramsal bilgileri iceren hesaplanan tekil degerler S k ile terim ve belge vektor uzaylarini tanimlar Bu uzaylardaki terimlerin veya belgelerin benzerligi bunlarin bu uzaylarda birbirlerine ne kadar yakin olduklarinin bir faktorudur ve genellikle karsilik gelen vektorler arasindaki acinin bir fonksiyonu olarak hesaplanir Mevcut bir LSI dizininin belge alaninda sorgularin ve yeni belgelerin metinlerini temsil eden vektorleri bulmak icin ayni adimlar kullanilir A TSD T denkleminin esdeger D A T TS 1 denklemine basit bir donusumuyle A da yeni bir sutun hesaplanip ardindan yeni sutun TS 1 ile carpilarak bir sorgu veya yeni bir belge icin yeni bir vektor d olusturulabilir A daki yeni sutun baslangicta turetilen genel terim agirliklari kullanilarak hesaplanir ve ayni yerel agirliklandirma islevi sorgudaki veya yeni belgedeki terimlere uygulanir Bu sekilde vektor hesaplamanin bir dezavantaji yeni aranabilir belgeler eklerken orijinal endeks icin SVD asamasinda bilinmeyen terimlerin goz ardi edilmesidir Bu terimlerin orijinal metin koleksiyonundan turetilen kuresel agirliklar ve ogrenilen korelasyonlar uzerinde hicbir etkisi olmayacaktir Ancak yeni metin icin hesaplanan vektorler diger tum belge vektorleriyle benzerlik karsilastirmalari icin hala cok onemlidir Bu sekilde bir LSI indeksi icin belge vektor uzaylarinin yeni belgelerle genisletilmesi islemine katlama denir Katlama islemi yeni metnin yeni anlamsal icerigini hesaba katmasa da bu sekilde onemli sayida belge eklemek icerdikleri terimler ve kavramlar eklendikleri LSI dizininde iyi bir sekilde temsil edildigi surece sorgular icin yine de iyi sonuclar saglayacaktir Yeni bir belge kumesinin terimleri ve kavramlarinin bir LSI dizinine dahil edilmesi gerektiginde terim belge matrisi ve SVD yeniden hesaplanmali veya artimli bir guncelleme yontemine ornegin de aciklanan yonteme ihtiyac duyulur LSI nin ek kullanimlari Modern bilgi arama sistemleri icin metinle anlamsal bir temelde calisabilme yeteneginin onemli oldugu genel olarak kabul edilmektedir Sonuc olarak olceklenebilirlik ve performanstaki onceki zorluklarin ustesinden gelinmesiyle birlikte LSI kullanimi son yillarda onemli olcude genisledi LSI cesitli bilgi alma ve metin isleme uygulamalarinda kullaniliyor ancak birincil uygulamasi kavram arama ve otomatik belge kategorizasyonu olmustur LSI nin kullanildigi diger bazi yollar asagida listelenmistir Bilgi kesfi Hukumet Istihbarat toplulugu Yayincilik Otomatik belge siniflandirmasi eKesif Hukumet Istihbarat toplulugu Yayincilik Metin ozetleme eKesif Yayincilik Iliski kesfi Hukumet Istihbarat toplulugu Sosyal Aglar Bireylerin ve kuruluslarin baglanti cizelgelerinin otomatik olarak olusturulmasi Hukumet Istihbarat toplulugu Teknik makalelerin ve hibelerin gozden gecirenlerle eslestirilmesi Hukumet Cevrimici musteri destegi Musteri Yonetimi Belge yazarliginin belirlenmesi Egitim Goruntulerin otomatik anahtar kelime aciklamasi Yazilim kaynak kodunun anlasilmasi Yazilim Muhendisligi Spam filtreleme Sistem Yonetimi Bilgi gorsellestirme Egitim Hisse senedi getirisi tahmini Ruya Icerigi Analizi Psikoloji LSI isletmelerin dava sureclerine hazirlanmasina yardimci olmak amaciyla elektronik belge kesfi eKesif amaciyla giderek daha fazla kullaniliyor eKesifte buyuk yapilandirilmamis metin koleksiyonlarini kavramsal bir temele gore kumeleme kategorilere ayirma ve arama yetenegi esastir LSI kullanilarak yapilan kavram tabanli arama onde gelen saglayicilar tarafindan 2003 yili gibi erken bir tarihte eKesif surecine uygulanmistir LSI ye Yonelik Zorluklar LSI a yonelik ilk zorluklar olceklenebilirlik ve performansa odaklanmisti LSI diger bilgi alma tekniklerine kiyasla nispeten yuksek hesaplama performansi ve bellek gerektirir Ancak modern yuksek hizli islemcilerin kullanilmaya baslanmasi ve ucuz belleklerin bulunmasiyla bu hususlar buyuk olcude ortadan kalkti Bazi LSI uygulamalarinda matris ve SVD hesaplamalari yoluyla tamamen islenmis 30 milyondan fazla belgeyi iceren gercek dunya uygulamalari yaygindir LSI nin tamamen olceklenebilir sinirsiz sayida belge cevrimici egitim bir uygulamasi acik kaynakli yazilim paketinde yer almaktadir LSI daki bir diger zorluk ise SVD yi gerceklestirmek icin kullanilacak optimum boyut sayisinin belirlenmesindeki iddia edilen zorluktur Genel bir kural olarak daha az boyut bir metin koleksiyonunda yer alan kavramlarin daha genis karsilastirmalarina olanak tanirken daha fazla boyut kavramlarin daha spesifik veya daha alakali karsilastirmalarina olanak tanir Kullanilabilecek gercek boyut sayisi koleksiyondaki belge sayisiyla sinirlidir Arastirmalar orta buyuklukteki belge koleksiyonlari yuz binlerce belge icin genellikle yaklasik 300 boyutun ve daha buyuk belge koleksiyonlari milyonlarca belge icin belki de 400 boyutun en iyi sonuclari saglayacagini gostermistir Ancak son arastirmalar belge koleksiyonunun boyutuna ve dogasina bagli olarak 50 1000 boyutun uygun oldugunu gostermektedir LSI icin PCA veya benzer sekilde korunan varyans oranini kontrol ederek optimum boyutlulugu belirlemek uygun degildir Es anlamlilik testi veya eksik kelimelerin tahmini dogru boyutlulugu bulmanin iki olasi yontemidir LSI konulari denetimli ogrenme yontemlerinde ozellik olarak kullanildiginda ideal boyutlulugu bulmak icin tahmin hatasi olcumlerinden yararlanilabilir Ayrica bakiniz Temel bilesenler analizi Konu modeli Gizli Dirichlet tahsisi Referanslar Susan T Dumais 2005 Latent Semantic Analysis Annual Review of Information Science and Technology 38 188 230 doi 10 1002 aris 1440380105 US Patent 4 839 853 Archived from the original on 2017 12 02 now expired The Latent Semantic Indexing home page image topicmodels west uni koblenz de Archived from the original on 17 March 2023 Markovsky I 2012 Low Rank Approximation Algorithms Implementation Applications Springer 2012 ISBN 978 1 4471 2226 5 page needed Alain Lifchitz Sandra Jhean Larose Guy Denhiere 2009 Effect of tuned parameters on an LSA multiple choice questions answering model PDF Behavior Research Methods 41 4 1201 1209 arXiv 0811 0146 doi 10 3758 BRM 41 4 1201 PMID 19897829 S2CID 480826 1 2 Ramiro H Galvez Agustin Gravano 2017 Assessing the usefulness of online message board mining in automatic stock prediction systems Journal of Computational Science 19 1877 7503 doi 10 1016 j jocs 2017 01 001 hdl 11336 60065 1 2 Altszyler E Ribeiro S Sigman M Fernandez Slezak D 2017 The interpretation of dream meaning Resolving ambiguity using Latent Semantic Analysis in a small corpus of text Consciousness and Cognition 56 178 187 arXiv 1610 01520 doi 10 1016 j concog 2017 09 004 PMID 28943127 S2CID 195347873 Gerry J Elman October 2007 Automated Patent Examination Support A proposal Biotechnology Law Report 26 5 435 436 doi 10 1089 blr 2007 9896 Marc W Howard Michael J Kahana 1999 Contextual Variability and Serial Position Effects in Free Recall PDF APA PsycNet Direct Franklin M Zaromb et al 2006 Temporal Associations and Prior List Intrusions in Free Recall PDF Interspeech 2005 Nelson Douglas The University of South Florida Word Association Rhyme and Word Fragment Norms Retrieved May 8 2011 Genevieve Gorrell Brandyn Webb 2005 Generalized Hebbian Algorithm for Latent Semantic Analysis PDF Interspeech 2005 Archived from the original PDF on 2008 12 21 1 2 Matthew Brand 2006 Fast Low Rank Modifications of the Thin Singular Value Decomposition Linear Algebra and Its Applications 415 20 30 doi 10 1016 j laa 2005 07 021 MATLAB Archived from the original on 2014 02 28 Python Ding Yaguang Zhu Guofeng Cui Chenyang Zhou Jian Tao Liang 2011 A parallel implementation of Singular Value Decomposition based on Map Reduce and PARPACK Proceedings of 2011 International Conference on Computer Science and Network Technology pp 739 741 doi 10 1109 ICCSNT 2011 6182070 ISBN 978 1 4577 1587 7 S2CID 15281129 1 2 Deerwester Scott Dumais Susan T Furnas George W Landauer Thomas K Harshman Richard 1990 Indexing by latent semantic analysis Journal of the American Society for Information Science 41 6 391 407 CiteSeerX 10 1 1 108 8490 doi 10 1002 SICI 1097 4571 199009 41 6 lt 391 AID ASI1 gt 3 0 CO 2 9 Abedi Vida Yeasin Mohammed Zand Ramin 27 November 2014 Empirical study using network of semantically related associations in bridging the knowledge gap Journal of Translational Medicine 12 1 324 doi 10 1186 s12967 014 0324 9 PMC 4252998 PMID 25428570 Thomas Hofmann 1999 Probabilistic Latent Semantic Analysis Uncertainty in Artificial Intelligence arXiv 1301 6705 Salakhutdinov Ruslan and Geoffrey Hinton Semantic hashing RBM 500 3 2007 500 1 2 3 Deerwester S et al Improving Information Retrieval with Latent Semantic Indexing Proceedings of the 51st Annual Meeting of the American Society for Information Science 25 1988 pp 36 40 Benzecri J P 1973 L Analyse des Donnees Volume II L Analyse des Correspondences Paris France Dunod Furnas G W Landauer T K Gomez L M Dumais S T 1987 The vocabulary problem in human system communication Communications of the ACM 30 11 964 971 CiteSeerX 10 1 1 118 4768 doi 10 1145 32206 32212 S2CID 3002280 Landauer T et al Learning Human like Knowledge by Singular Value Decomposition A Progress Report M I Jordan M J Kearns amp S A Solla Eds Advances in Neural Information Processing Systems 10 Cambridge MIT Press 1998 pp 45 51 Dumais S Platt J Heckerman D Sahami M 1998 Inductive learning algorithms and representations for text categorization PDF Proceedings of the seventh international conference on Information and knowledge management CIKM 98 pp 148 CiteSeerX 10 1 1 80 8909 doi 10 1145 288627 288651 ISBN 978 1581130614 S2CID 617436 Homayouni R Heinrich K Wei L Berry M W 2004 Gene clustering by Latent Semantic Indexing of MEDLINE abstracts Bioinformatics 21 1 104 115 doi 10 1093 bioinformatics bth464 PMID 15308538 Price R J Zukas A E 2005 Application of Latent Semantic Indexing to Processing of Noisy Text Intelligence and Security Informatics Lecture Notes in Computer Science Vol 3495 p 602 doi 10 1007 11427995 68 ISBN 978 3 540 25999 2 Ding C A Similarity based Probability Model for Latent Semantic Indexing Proceedings of the 22nd International ACM SIGIR Conference on Research and Development in Information Retrieval 1999 pp 59 65 Bartell B Cottrell G and Belew R Latent Semantic Indexing is an Optimal Special Case of Multidimensional Scaling dead link Proceedings ACM SIGIR Conference on Research and Development in Information Retrieval 1992 pp 161 167 Graesser A Karnavat A 2000 Latent Semantic Analysis Captures Causal Goal oriented and Taxonomic Structures Proceedings of CogSci 2000 184 189 CiteSeerX 10 1 1 23 5444 Dumais S Nielsen J 1992 Automating the assignment of submitted manuscripts to reviewers Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval SIGIR 92 pp 233 244 CiteSeerX 10 1 1 16 9793 doi 10 1145 133160 133205 ISBN 978 0897915236 S2CID 15038631 Berry M W and Browne M Understanding Search Engines Mathematical Modeling and Text Retrieval Society for Industrial and Applied Mathematics Philadelphia 2005 Landauer T et al Handbook of Latent Semantic Analysis Lawrence Erlbaum Associates 2007 Berry Michael W Dumais Susan T O Brien Gavin W Using Linear Algebra for Intelligent Information Retrieval December 1994 SIAM Review 37 4 1995 pp 573 595 Dumais S Latent Semantic Analysis ARIST Review of Information Science and Technology vol 38 2004 Chapter 4 Best Practices Commentary on the Use of Search and Information Retrieval Methods in E Discovery the Sedona Conference 2007 pp 189 223 Foltz P W and Dumais S T Personalized Information Delivery An analysis of information filtering methods Communications of the ACM 1992 34 12 51 60 Gong Y and Liu X Creating Generic Text Summaries Proceedings Sixth International Conference on Document Analysis and Recognition 2001 pp 903 907 Bradford R Efficient Discovery of New Information in Large Text Databases Proceedings IEEE International Conference on Intelligence and Security Informatics Atlanta Georgia LNCS Vol 3495 Springer 2005 pp 374 380 Bradford R B 2006 Application of Latent Semantic Indexing in Generating Graphs of Terrorist Networks Intelligence and Security Informatics Lecture Notes in Computer Science Vol 3975 pp 674 675 doi 10 1007 11760146 84 ISBN 978 3 540 34478 0 Yarowsky D and Florian R Taking the Load off the Conference Chairs Towards a Digital Paper routing Assistant Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in NLP and Very Large Corpora 1999 pp 220 230 Caron J Applying LSA to Online Customer Support A Trial Study Unpublished Master s Thesis May 2000 Soboroff I et al Visualizing Document Authorship Using N grams and Latent Semantic Indexing Workshop on New Paradigms in Information Visualization and Manipulation 1997 pp 43 48 Monay F and Gatica Perez D On Image Auto annotation with Latent Space Models Proceedings of the 11th ACM international conference on Multimedia Berkeley CA 2003 pp 275 278 Maletic J Marcus A November 13 15 2000 Using latent semantic analysis to identify similarities in source code to support program understanding Proceedings 12th IEEE Internationals Conference on Tools with Artificial Intelligence ICTAI 2000 pp 46 53 CiteSeerX 10 1 1 36 6652 doi 10 1109 TAI 2000 889845 ISBN 978 0 7695 0909 9 S2CID 10354564 Gee K Using Latent Semantic Indexing to Filter Spam in Proceedings 2003 ACM Symposium on Applied Computing Melbourne Florida pp 460 464 Landauer T Laham D and Derr M From Paragraph to Graph Latent Semantic Analysis for Information Visualization Proceedings of the National Academy of Sciences 101 2004 pp 5214 5219 Foltz Peter W Laham Darrell and Landauer Thomas K Automated Essay Scoring Applications to Educational Technology Proceedings of EdMedia 1999 Gordon M and Dumais S Using Latent Semantic Indexing for Literature Based Discovery Journal of the American Society for Information Science 49 8 1998 pp 674 685 There Has to be a Better Way to Search 2008 White Paper Fios Inc Karypis G Han E Fast Supervised Dimensionality Reduction Algorithm with Applications to Document Categorization and Retrieval Proceedings of CIKM 00 9th ACM Conference on Information and Knowledge Management Radim Rehurek 2011 Subspace Tracking for Latent Semantic Analysis Advances in Information Retrieval Lecture Notes in Computer Science Vol 6611 pp 289 300 doi 10 1007 978 3 642 20161 5 29 ISBN 978 3 642 20160 8 Bradford R An Empirical Study of Required Dimensionality for Large scale Latent Semantic Indexing Applications Proceedings of the 17th ACM Conference on Information and Knowledge Management Napa Valley California USA 2008 pp 153 162 Landauer Thomas K and Dumais Susan T Latent Semantic Analysis Scholarpedia 3 11 4356 2008 Landauer T K Foltz P W amp Laham D 1998 Introduction to Latent Semantic Analysis Discourse Processes 25 259 284 Susan T Dumais 2005 Latent Semantic Analysis Annual Review of Information Science and Technology 38 188 230 doi 10 1002 aris 1440380105 US Patent 4 839 853 2 Aralik 2017 tarihinde kaynagindan arsivlendi now expired The Latent Semantic Indexing home page 3 Aralik 1998 tarihinde kaynagindan arsivlendi image topicmodels west uni koblenz de 17 Mart 2023 tarihinde kaynagindan arsivlendi Markovsky I 2012 Low Rank Approximation Algorithms Implementation Applications Springer 2012 978 1 4471 2226 5 sayfa belirt Alain Lifchitz Sandra Jhean Larose Guy Denhiere 2009 Effect of tuned parameters on an LSA multiple choice questions answering model PDF Behavior Research Methods 41 4 1201 1209 arXiv 0811 0146 2 doi 10 3758 BRM 41 4 1201 PMID 19897829 14 Mayis 2012 tarihinde kaynagindan arsivlendi PDF Erisim tarihi free Tarih degerini gozden gecirin erisimtarihi yardim a b Ramiro H Galvez Agustin Gravano 2017 Assessing the usefulness of online message board mining in automatic stock prediction systems Journal of Computational Science 19 1877 7503 doi 10 1016 j jocs 2017 01 001 a b Altszyler E Ribeiro S Sigman M Fernandez Slezak D 2017 The interpretation of dream meaning Resolving ambiguity using Latent Semantic Analysis in a small corpus of text Consciousness and Cognition 56 178 187 arXiv 1610 01520 2 doi 10 1016 j concog 2017 09 004 PMID 28943127 Gerry J Elman October 2007 Automated Patent Examination Support A proposal Biotechnology Law Report 26 5 435 436 doi 10 1089 blr 2007 9896 Marc W Howard Michael J Kahana 1999 Contextual Variability and Serial Position Effects in Free Recall PDF APA PsycNet Direct Franklin M Zaromb ve digerleri 2006 Temporal Associations and Prior List Intrusions in Free Recall PDF Interspeech 2005 16 Mart 2023 tarihinde kaynagindan arsivlendi PDF Erisim tarihi 21 Nisan 2025 Nelson Douglas The University of South Florida Word Association Rhyme and Word Fragment Norms 1 Eylul 2011 tarihinde kaynagindan arsivlendi Erisim tarihi 8 Mayis 2011 Genevieve Gorrell Brandyn Webb 2005 Generalized Hebbian Algorithm for Latent Semantic Analysis PDF Interspeech 2005 21 Aralik 2008 tarihinde kaynagindan PDF arsivlendi a b Matthew Brand 2006 Fast Low Rank Modifications of the Thin Singular Value Decomposition Linear Algebra and Its Applications 415 20 30 doi 10 1016 j laa 2005 07 021 Erisim tarihi free Tarih degerini gozden gecirin erisimtarihi yardim MATLAB 28 Subat 2014 tarihinde kaynagindan arsivlendi Python 21 Nisan 2025 tarihinde kaynagindan arsivlendi Erisim tarihi 21 Nisan 2025 Ding Yaguang Zhu Guofeng Cui Chenyang Zhou Jian Tao Liang 2011 A parallel implementation of Singular Value Decomposition based on Map Reduce and PARPACK Proceedings of 2011 International Conference on Computer Science and Network Technology ss 739 741 doi 10 1109 ICCSNT 2011 6182070 ISBN 978 1 4577 1587 7 a b Deerwester Scott Dumais Susan T Furnas George W Landauer Thomas K Harshman Richard 1990 Indexing by latent semantic analysis Journal of the American Society for Information Science 41 6 391 407 doi 10 1002 SICI 1097 4571 199009 41 6 lt 391 AID ASI1 gt 3 0 CO 2 9 Abedi Vida Yeasin Mohammed Zand Ramin 27 Kasim 2014 Empirical study using network of semantically related associations in bridging the knowledge gap Journal of Translational Medicine 12 1 324 doi 10 1186 s12967 014 0324 9 PMC 4252998 2 PMID 25428570 Salakhutdinov Ruslan and Geoffrey Hinton Semantic hashing RBM 500 3 2007 500 a b c Deerwester S et al Improving Information Retrieval with Latent Semantic Indexing Proceedings of the 51st Annual Meeting of the American Society for Information Science 25 1988 pp 36 40 Benzecri J P 1973 L Analyse des Donnees Volume II L Analyse des Correspondences Paris France Dunod Furnas G W Landauer T K Gomez L M Dumais S T 1987 The vocabulary problem in human system communication Communications of the ACM 30 11 964 971 doi 10 1145 32206 32212 Landauer T et al Learning Human like Knowledge by Singular Value Decomposition A Progress Report 25 Ekim 2020 tarihinde Wayback Machine sitesinde arsivlendi M I Jordan M J Kearns amp Eds Advances in Neural Information Processing Systems 10 Cambridge MIT Press 1998 pp 45 51 Dumais S Platt J Heckerman D Sahami M 1998 Inductive learning algorithms and representations for text categorization PDF Proceedings of the seventh international conference on Information and knowledge management CIKM 98 ss 148 doi 10 1145 288627 288651 ISBN 978 1581130614 Homayouni R Heinrich K Wei L Berry M W 2004 Gene clustering by Latent Semantic Indexing of MEDLINE abstracts Bioinformatics 21 1 104 115 doi 10 1093 bioinformatics bth464 PMID 15308538 Price R J Zukas A E 2005 Application of Latent Semantic Indexing to Processing of Noisy Text Intelligence and Security Informatics Lecture Notes in Computer Science 3495 s 602 doi 10 1007 11427995 68 ISBN 978 3 540 25999 2 Ding C A Similarity based Probability Model for Latent Semantic Indexing Proceedings of the 22nd International ACM SIGIR Conference on Research and Development in Information Retrieval 1999 pp 59 65 Bartell B Cottrell G and Belew R Latent Semantic Indexing is an Optimal Special Case of Multidimensional Scaling olu kirik baglanti Proceedings ACM SIGIR Conference on Research and Development in Information Retrieval 1992 pp 161 167 Graesser A Karnavat A 2000 Latent Semantic Analysis Captures Causal Goal oriented and Taxonomic Structures Proceedings of CogSci 2000 184 189 Dumais S Nielsen J 1992 Automating the assignment of submitted manuscripts to reviewers Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval SIGIR 92 ss 233 244 doi 10 1145 133160 133205 ISBN 978 0897915236 Berry M W and Browne M Understanding Search Engines Mathematical Modeling and Text Retrieval Society for Industrial and Applied Mathematics Philadelphia 2005 Landauer T et al Handbook of Latent Semantic Analysis Lawrence Erlbaum Associates 2007 Berry Michael W Dumais Susan T O Brien Gavin W Using Linear Algebra for Intelligent Information Retrieval 26 Nisan 2025 tarihinde Wayback Machine sitesinde arsivlendi December 1994 SIAM Review 37 4 1995 pp 573 595 Dumais S Latent Semantic Analysis ARIST Review of Information Science and Technology vol 38 2004 Chapter 4 Best Practices Commentary on the Use of Search and Information Retrieval Methods in E Discovery the Sedona Conference 2007 pp 189 223 Foltz P W and Dumais S T Personalized Information Delivery An analysis of information filtering methods Communications of the ACM 1992 34 12 51 60 Gong Y and Liu X Creating Generic Text Summaries 15 Nisan 2024 tarihinde Wayback Machine sitesinde arsivlendi Proceedings Sixth International Conference on Document Analysis and Recognition 2001 pp 903 907 Bradford R Efficient Discovery of New Information in Large Text Databases Proceedings IEEE International Conference on Intelligence and Security Informatics Atlanta Georgia LNCS Vol 3495 Springer 2005 pp 374 380 Bradford R B 2006 Application of Latent Semantic Indexing in Generating Graphs of Terrorist Networks Intelligence and Security Informatics Lecture Notes in Computer Science 3975 ss 674 675 doi 10 1007 11760146 84 ISBN 978 3 540 34478 0 Yarowsky D and Florian R Taking the Load off the Conference Chairs Towards a Digital Paper routing Assistant 8 Agustos 2019 tarihinde Wayback Machine sitesinde arsivlendi Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in NLP and Very Large Corpora 1999 pp 220 230 Caron J Applying LSA to Online Customer Support A Trial Study Unpublished Master s Thesis May 2000 Soboroff I et al Visualizing Document Authorship Using N grams and Latent Semantic Indexing Workshop on New Paradigms in Information Visualization and Manipulation 1997 pp 43 48 Monay F and Gatica Perez D On Image Auto annotation with Latent Space Models 17 Agustos 2017 tarihinde Wayback Machine sitesinde arsivlendi Proceedings of the 11th ACM international conference on Multimedia Berkeley CA 2003 pp 275 278 Maletic J Marcus A November 13 15 2000 Using latent semantic analysis to identify similarities in source code to support program understanding Proceedings 12th IEEE Internationals Conference on Tools with Artificial Intelligence ICTAI 2000 ss 46 53 doi 10 1109 TAI 2000 889845 ISBN 978 0 7695 0909 9 Gee K Using Latent Semantic Indexing to Filter Spam in Proceedings 2003 ACM Symposium on Applied Computing Melbourne Florida pp 460 464 Landauer T Laham D and Derr M From Paragraph to Graph Latent Semantic Analysis for Information Visualization 21 Ocak 2022 tarihinde Wayback Machine sitesinde arsivlendi Proceedings of the National Academy of Sciences 101 2004 pp 5214 5219 Foltz Peter W Laham Darrell and Landauer Thomas K Automated Essay Scoring Applications to Educational Technology Proceedings of EdMedia 1999 Gordon M and Dumais S Using Latent Semantic Indexing for Literature Based Discovery 10 Subat 2023 tarihinde Wayback Machine sitesinde arsivlendi Journal of the American Society for Information Science 49 8 1998 pp 674 685 There Has to be a Better Way to Search 2008 White Paper Fios Inc Karypis G Han E Fast Supervised Dimensionality Reduction Algorithm with Applications to Document Categorization and Retrieval Proceedings of CIKM 00 9th ACM Conference on Information and Knowledge Management Radim Rehurek 2011 Subspace Tracking for Latent Semantic Analysis Advances in Information Retrieval Lecture Notes in Computer Science 6611 ss 289 300 doi 10 1007 978 3 642 20161 5 29 ISBN 978 3 642 20160 8 Bradford R An Empirical Study of Required Dimensionality for Large scale Latent Semantic Indexing Applications 2 Ocak 2018 tarihinde Wayback Machine sitesinde arsivlendi Proceedings of the 17th ACM Conference on Information and Knowledge Management Napa Valley California USA 2008 pp 153 162 Landauer Thomas K and Dumais Susan T Latent Semantic Analysis Scholarpedia 3 11 4356 2008 Landauer T K Foltz P W amp Laham D 1998 Introduction to Latent Semantic Analysis Discourse Processes 25 259 284 Daha fazla okuma Landauer Thomas Foltz Peter W Laham Darrell 1998 Introduction to Latent Semantic Analysis PDF Discourse Processes 25 2 3 259 284 doi 10 1080 01638539809545028 Deerwester Scott Dumais Susan T Furnas George W Landauer Thomas K Harshman Richard 1990 Indexing by Latent Semantic Analysis PDF Journal of the American Society for Information Science 41 6 391 407 doi 10 1002 SICI 1097 4571 199009 41 6 lt 391 AID ASI1 gt 3 0 CO 2 9 17 Temmuz 2012 tarihinde kaynagindan PDF arsivlendi Original article where the model was first exposed Berry Michael Dumais Susan T O Brien Gavin W 1995 Using Linear Algebra for Intelligent Information Retrieval 23 Subat 2008 tarihinde kaynagindan arsivlendi PDF Archived 2018 11 23 at the Wayback Machine Illustration of the application of LSA to document retrieval Chicco D Masseroli M 2015 Software suite for gene and protein annotation prediction and similarity search IEEE ACM Transactions on Computational Biology and Bioinformatics 12 4 837 843 doi 10 1109 TCBB 2014 2382127 PMID 26357324 Latent Semantic Analysis InfoVis 18 Subat 2020 tarihinde kaynagindan arsivlendi Erisim tarihi 1 Temmuz 2005 Fridolin Wild 23 Kasim 2005 An Open Source LSA Package for R CRAN 10 Eylul 2016 tarihinde kaynagindan arsivlendi Erisim tarihi 20 Kasim 2006 A Solution to Plato s Problem The Latent Semantic Analysis Theory of Acquisition Induction and Representation of Knowledge 26 Ocak 2025 tarihinde kaynagindan arsivlendi Erisim tarihi 2 Temmuz 2007 Dis baglantilar LSA ile ilgili makaleler Latent Semantic Analysis LSA nin yaraticilarindan Tom Landauer in LSA hakkinda yazdigi bir scholarpedia makalesidir Konusmalar ve gosteriler LSA Genel Bakis Prof Thomas Hofmann in konusmasi Archived LSA yi Bilgi Alma daki uygulamalarini ve baglantilarini aciklayan Windows icin C dilinde tam LSA ornek kodu Demo kodu metin dosyalarinin numaralandirilmasi durdurma sozcuklerinin filtrelenmesi koklendirme belge terim matrisi olusturulmasi ve SVD yi icermektedir Uygulamalar Bilgi Alma Dogal Dil Isleme NLP Bilissel Bilimler ve Hesaplamali Dilbilim alanlarindaki alanlar arasi uygulamalari nedeniyle LSA pek cok farkli turde uygulamayi desteklemek icin uygulanmistir Sense Clusters LSA nin Bilgi Alma odakli bir Perl uygulamasidir S Space Paketi LSA nin Hesaplamali Dilbilim ve Bilissel Bilim odakli Java uygulamasidir Semantic Vectors Lucene terim belge matrislerine Rastgele Projeksiyon LSA ve Yansitici Rastgele Indeksleme uygular Infomap Projesi LSA nin NLP odakli bir C uygulamasidir semanticvectors projesi tarafindan degistirilmistir Metinden Matris Olusturucu adresinde Archived LSA destegiyle metin koleksiyonlarindan terim belge matrisleri olusturmak icin bir MATLAB Arac Kutusu RAM den buyuk matrisler icin LSA nin Python uygulamasini icerir